When we run a statistical model, we are in a sense creating a mathematical equation. The simplest regression model looks like this:
Yi = β0 + β1X+ εi
The left side of the equation is the sum of two parts on the right: the fixed component, β0 + β1X, and the random component, εi.
You’ll also sometimes see the equation written about the mean or expected value of Y on the left and only the fixed component on the right:
μY|X = β0 + β1X
All we’ve done is remove that random component from both sides to focus on the fixed portion. Why?
The random component has a probability distribution. Since the outcome variable Y includes that random component, it too follows a probability distribution.
In linear regression, we assume that probability distribution is normal. But there are a lot of outcome variables for which a normal distribution doesn’t fit.
Generalized Linear Models
Generalized linear models allow a few other distributions, including Poisson, binomial, and Gamma (among others).
But in order to make the model fit in a linear form for these other distributions, we often need to take some function of the mean. That second equation above doesn’t fit.
In generalized linear models, there is a link function, which is the link between the mean of Y on the left and the fixed component on the right.
f(μY|X) = β0 + β1X
It’s very possible you have run models without being aware of this. Some software packages have models (e.g., Stata’s nbreg or SAS proc logistic) that use a default link function.
But if you run a generalized linear model in a more general software procedure (like SAS’s proc genmod or R’s glm), then you must select the link function that works with the distribution in the random components.
A natural fit for count variables that follow the Poisson or negative binomial distribution is the log link. The log link exponentiates the linear predictors. It does not log transform the outcome variable.
Here are two versions of the same basic model equation for count data:
ln(μ) = β0 + β1X
μ = exp(β0 + β1X), also written as μ = eβ0 + β1X
Where μ=predicted value of Y given X, exp(β0) = the effect on the mean of μ when X=0, and exp(β1)= the multiplicative effect on the mean of Y for a one-unit increase in X. e is a constant value of approximately 2.72.
There are several link choices for each probability distribution. The table below shows the potential combinations allowed in Stata.
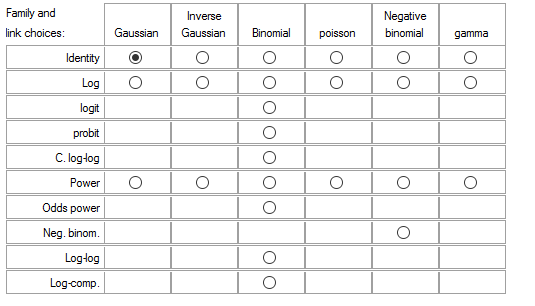
But there is generally a best fitting link for each distribution, the canonical link. Be sure to choose the best fit.
**This article was updated Nov. 12th, 2020.
Jeff Meyer is a statistical consultant with The Analysis Factor, a stats mentor for Statistically Speaking membership, and a workshop instructor. Read more about Jeff here.

This article explains very nicely how the error term (and the response variable Y) in simple linear regression are assumed to follow a normal distribution.
But what happens to the error term in GLMs? All I see is the fixed component on the right.
Hi Barry,
There isn’t an error term in Generalized Linear Models. See: https://www.theanalysisfactor.com/generalized-linear-models-no-error-term/