new blog post: Member Training: The Dark Side of Data Science

Previous Posts
Statistical models, such as general linear models (linear regression, ANOVA, MANOVA), linear mixed models, and generalized linear models (logistic, Poisson, regression, etc.) all have the same general form. On the left side of the equation is one or more response variables, Y. On the right hand side is one or more predictor variables, X, and […]
I was recently asked about when to use one and two tailed tests. The long answer is: Use one tailed tests when you have a specific hypothesis about the direction of your relationship. Some examples include you hypothesize that one group mean is larger than the other; you hypothesize that the correlation is positive; you […]
A great article for specifying Mixed Models in SAS: Mixed up Mixed Models by Robert Harner & P.M. Simpson Anyone doing mixed modeling in SAS should read this paper, originally presented at SUGI: SAS Users Group International conference. It compares the output from Proc Mixed and Proc GLM when specified different ways. There are some […]
I just wanted to follow up on my last post about Regression without Intercepts. Regression through the Origin means that you purposely drop the intercept from the model. When X=0, Y must = 0. The thing to be careful about in choosing any regression model is that it fit the data well. Pretty much the […]
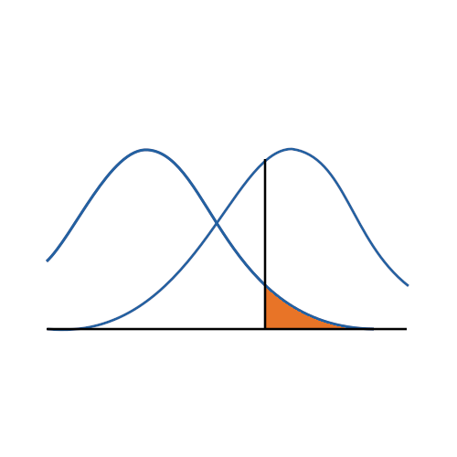
Nearly all granting agencies require an estimate of an adequate sample size to detect the effects hypothesized in the study. But all studies are well served by estimates of sample size, as it can save a great deal on resources. Why? Undersized studies can’t find real results, and oversized studies find even insubstantial ones. Both […]
One of the main assumptions of linear models such as linear regression and analysis of variance is that the residual errors follow a normal distribution. To meet this assumption when a continuous response variable is skewed, a transformation of the response variable can produce errors that are approximately normal. Often, however, the response variable of […]
With SAS, it’s almost always the semicolons! I read that recently–I can’t remember where now (if you wrote it, let me know–I’ll link!). I spent the day at Cornell doing SAS programming; I kept expecting Andy Bernard to show up. Anyway, I was reminded of that quote because, as you guessed it, it was almost […]
My next door neighbor, who is a mycologist (hey, it’s Ithaca–everyone’s a researcher here) asked me a very common statistical question–she was very concerned about her unequal sample sizes. She was doing a chi-square test and had about 11 observations in one grouping and 18 in the other. She had already talked with a statistical […]
A previous post discussed the first reason to not use mean imputation as a way of dealing with missing data–it does not preserve the relationships among variables. A second reason is that any type of single imputation underestimates error variation in any statistic that used the imputed data. Because the imputations are themselves estimates, there […]
Researchers are often interested in setting up a model to analyze the relationship between some predictors (i.e., independent variables) and a response (i.e., dependent variable). Linear regression is commonly used when the response variable is continuous. One assumption of linear models is that the residual errors follow a normal distribution. This assumption fails when the […]
 stat skill-building compass
stat skill-building compass