One of the most common—and one of the trickiest—challenges in data analysis is deciding how to include multiple predictors in a model, especially when they’re related to each other.

Let’s say you are interested in studying the relationship between work spillover into personal time as a predictor of job burnout.
You have 5 categorical yes/no variables that indicate whether a particular symptom of work spillover is present (see below).
While you could use each individual variable, you’re not really interested if one in particular is related to the outcome. Perhaps it’s not really each symptom that’s important, but the idea that spillover is happening.
(more…)
One question that seems to come up pretty often is:
What is the difference between logistic and probit regression?
Well, let’s start with how they’re the same:
Both are types of generalized linear models. This means they have this form:
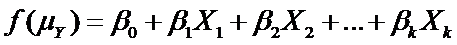
(more…)
Here’s a common situation.
Your grant application or committee requires sample size estimates. It’s not the calculations that are hard (though they can be), it’s getting the information to fill into the calculations.
Every article you read on it says you need to either use pilot data or another similar study as a basis for the values to enter into the software.
You have neither.
No similar studies have ever used the scale you’re using for the dependent variable.
And while you’d love to run a pilot study, it’s just not possible. There are too many practical constraints — time, money, distance, ethics.
What do you do?
(more…)
We’ve talked a lot around here about the reasons to use syntax — not only menus — in your statistical analyses.
Regardless of which software you use, the syntax file is pretty much always a text file. This is true for R, SPSS, SAS, Stata — just about all of them.
This is important because it means you can use an unlikely tool to help you code: Microsoft Word.
I know what you’re thinking. Word? Really?
Yep, it’s true. Essentially it’s because Word has much better Search-and-Replace options than your stat software’s editor.
Here are a couple features of Word’s search-and-replace that I use to help me code faster:
(more…)
I recently gave a free webinar on Principal Component Analysis. We had almost 300 researchers attend and didn’t get through all the questions. This is part of a series of answers to those questions.
If you missed it, you can get the webinar recording here.
Question: How do we decide whether to have rotated or unrotated factors?
Answer:
Great question. Of course, the answer depends on your situation.
When you retain only one factor in a solution, then rotation is irrelevant. In fact, most software won’t even print out rotated coefficients and they’re pretty meaningless in that situation.
But if you retain two or more factors, you need to rotate.
Unrotated factors are pretty difficult to interpret in that situation. (more…)
I recently gave a free webinar on Principal Component Analysis. We had almost 300 researchers attend and didn’t get through all the questions. This is part of a series of answers to those questions.
If you missed it, you can get the webinar recording here.
Question: Can you use Principal Component Analysis with a Training Set Test Set Model?
Answer: Yes and no.
Principal Component Analysis specifically could be used with a training and test data set, but it doesn’t make as much sense as doing so for Factor Analysis.
That’s because PCA is really just about creating an index variable from a set of correlated predictors.
Factor Analysis is an actual model that is measuring a latent variable. Any time you’re creating some sort of scale to measure an underlying construct, you want to use Factor Analysis.
Factor Analysis is definitely best done with a training and test data set.
In fact, ideally, you’d run multiple rounds of training and test data sets, in which the variables included on your scale are updated after each test. (more…)