 There are a number of simplistic methods available for tackling the problem of missing data. Unfortunately there is a very high likelihood that each of these simplistic methods introduces bias into our model results.
There are a number of simplistic methods available for tackling the problem of missing data. Unfortunately there is a very high likelihood that each of these simplistic methods introduces bias into our model results.
Multiple imputation is considered to be the superior method of working with missing data. It eliminates the bias introduced by the simplistic methods in many missing data situations.
Missing data can be broken down into three distinct missing patterns:
- monotone with continuous variables,
- non-monotone with continuous variables, and
- non-monotone with all types of variables.
You will learn these three patterns, the importance of understanding which you have, and the process of multiple imputation for all three patterns.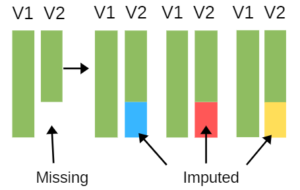
By the end of the training you will have a good understanding of how to get started imputing your missing data.
Note: This training is an exclusive benefit to members of the Statistically Speaking Membership Program and part of the Stat’s Amore Trainings Series. Each Stat’s Amore Training is approximately 90 minutes long.
About the Instructor

Jeff Meyer is a statistical consultant and the Stata expert at The Analysis Factor. He teaches workshops and provides Stata examples for a number of our workshops, including Intro to Stata, Missing Data, and Repeated Measures.
Jeff has an MBA from the Thunderbird School of Global Management and an MPA with a focus on policy from NYU Wagner School of Public Service.
Just head over and sign up for Statistically Speaking. You'll get access to this training webinar, 130+ other stats trainings, a pathway to work through the trainings that you need — plus the expert guidance you need to build statistical skill with live Q&A sessions and an ask-a-mentor forum.