At times it is necessary to convert a continuous predictor into a categorical predictor. For example, income per household is shown below.
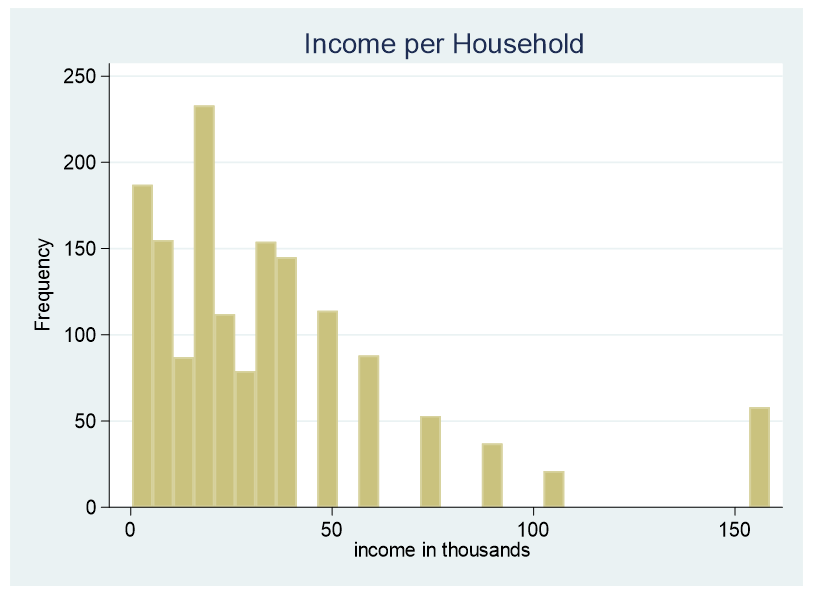
This data is censored, all family income above $155,000 is stated as $155,000. A further explanation about censored and truncated data can be found here. It would be incorrect to use this variable as a continuous predictor due to its censoring.
(more…)
Smoothing can assist data analysis by highlighting important trends and revealing long term movements in time series that otherwise can be hard to see.
Many data smoothing techniques have been developed, each of which may be useful for particular kinds of data and in specific applications. David will give an introductory overview of the most common smoothing methods, and will show examples of their use. He will cover moving averages, exponential smoothing, the Kalman Filter, low-pass filters, high pass filters, LOWESS and smoothing splines.
This presentation is pitched towards those who may use smoothing techniques during the course of their analytic work, but who have little familiarity with the techniques themselves. David will avoid the underpinning mathematical and statistical methods, but instead will focus on providing a clear understanding of what each technique is about.
Note: This training is an exclusive benefit to members of the Statistically Speaking Membership Program and part of the Stat’s Amore Trainings Series. Each Stat’s Amore Training is approximately 90 minutes long.
(more…)