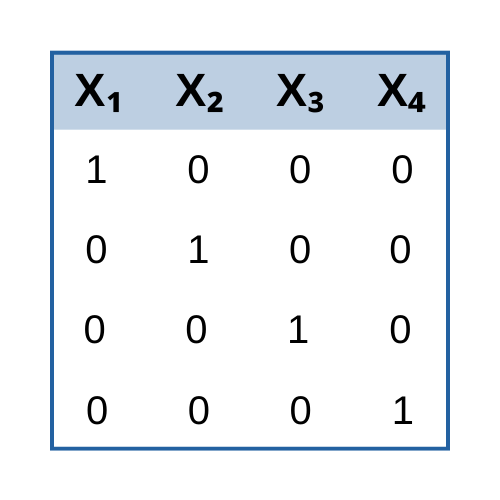
new blog post: Member Training: Dummy and Effect Coding
Previous Posts
Most Multiple Imputation methods assume multivariate normality, so a common question is how to impute missing values from categorical variables. Paul Allison, one of my favorite authors of statistical information for researchers, did a study that showed that the most common method actually gives worse results that listwise deletion. (Did I mention I’ve used it […]
I was recently asked about whether it's okay to treat a likert scale as continuous in a regression model. Here's my reply.
In choosing an approach to missing data, there are a number of things to consider. But you need to keep in mind what you're aiming for before you can even consider which appraoch to take. There are three criteria we're aiming for with any missing data technique:
There are two ways to run a repeated measures analysis. The traditional way is to treat it as a multivariate test--each response is considered a separate variable. The other way is to it as a mixed model. While the multivariate approach is easy to run and quite intuitive, there are a number of advantages to running a repeated measures analysis as a mixed model.
The way to follow up on a significant two-way interaction between two categorical variables is to check the simple effects. Every so often, however, you have a significant interaction, but no significant simple effects. It is not a logical impossibility. They are testing two different, but related hypotheses.
Logistic regression models can seem pretty overwhelming to the uninitiated. Why not use a regular regression model? Just turn Y into an indicator variable--Y=1 for success and Y=0 for failure. For some good reasons.
Regression models are just a subset of the General Linear Model, so you can use GLMs to analyze regressions. It is what I usually use. But in SPSS there are options available in the GLM and Regression procedures that aren't available in the other. How do you decide when to use GLM and when to use Regression?
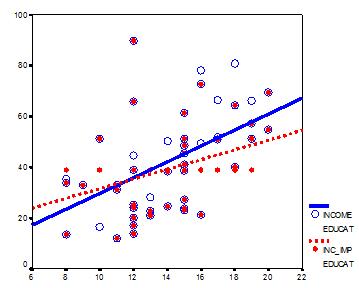
I’m sure I don’t need to explain to you all the problems that occur as a result of missing data. Anyone who has dealt with missing data—that means everyone who has ever worked with real data—knows about the loss of power and sample size, and the potential bias in your data that comes with listwise […]
The distributional assumptions for linear regression and ANOVA are for the distribution of Y|X -- that's Y given X. You have to take out the effects of all the Xs before you look at the distribution of Y.
I often hear concern about the non-normal distributions of independent variables in regression models, and I am here to ease your mind. There are NO assumptions in any linear model about the distribution of the independent variables. Yes, you only get meaningful parameter estimates from nominal (unordered categories) or numerical (continuous or discrete) independent variables. […]
 stat skill-building compass
stat skill-building compass