new blog post: Member Training: Dummy and Effect Coding
Previous Posts
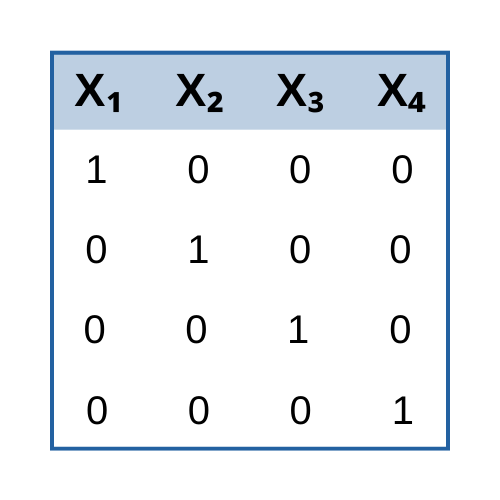
But it can be very useful and legitimate to be able to choose whether to treat an independent variable as categorical or continuous. Knowing when it is appropriate and understanding how it affects interpretion of parameters allows the data analyst to find real results that might otherwise have been missed.
One of the basic tenets of statistics that every student learns in about the second week of intro stats is that in a skewed distribution, the mean is closer to the tail in a skewed distribution.
As I contentedly followed the steps in the algorithm, I couldn't help but wonder why it worked. What did the steps really mean, and why did they work on any messed up cube? But it was also clear to me that I'd have to blindly work through those steps a number of times before it made any sense to me. The important point for the first run was to just obey and make sure it worked.
A new version of Amelia II, a free package for multiple imputation, has just been released today.
It's true that median splits are arbitrary, but there are situations when it is reasonable to make a continuous numerical variable categorical.
I was recently asked this question about Chi-square tests. This question comes up a lot, so I thought I'd share my answer. I have to compare two sets of categorical data in a 2x4 table. I cannot run the chi-square test because most of the cells contain values less than five and a couple of them contain values of 0. Is there any other test that I could use that overcomes the limitations of chi-square?
An excellent handbook that outlines how to prepare the statistical content for grant proposals is "Statistics Guide for Research Grant Applicants." Sections include "Describing the Study Design", "Sample Size Calculations", and "Describing the Statistical Methods," among others.
So over the years, a number of ad hoc approaches have been proposed to stop the bloodletting of so much data. Although each solved some problems of listwise deletion, they created others. All three have been discredited in recent years and should NOT be used.
To increase power: 1. Increase alpha 2. Conduct a one-tailed test 3. Increase the effect size
Some approaches to missing data work well in some situations, but perform very poorly in others. So it's really important to get a good idea of the type and pattern of missingness in your data. You may even take different missing data approaches to different variables.
 stat skill-building compass
stat skill-building compass