Have you ever worked with a data set that had so many observations and/or variables that you couldn’t see the forest for the trees? You would like to extract some simple information but you can’t quite figure out how to do it.
Get to know Stata’s collapse command–it’s your new friend. Collapse allows you to convert your current data set to a much smaller data set of means, medians, maximums, minimums, count or percentiles (your choice of which percentile).
Let’s take a look at an example. I’m currently looking at a longitudinal data set filled with economic data on all 67 counties in Alabama. The time frame is in decades, from 1960 to 2000. Five time periods by 67 counties give me a total of 335 observations.
What if I wanted to see some trend information, such as the total population and jobs per decade for all of Alabama? I just want a simple table to see my results as well as a graph. I want results that I can copy and paste into a Word document.
Here’s my code:
preserve
collapse (sum) Pop Jobs, by(year)
graph twoway (line Pop year) (line Jobs year), ylabel(, angle(horizontal))
list
And here is my output:
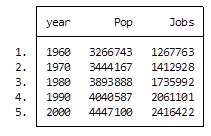
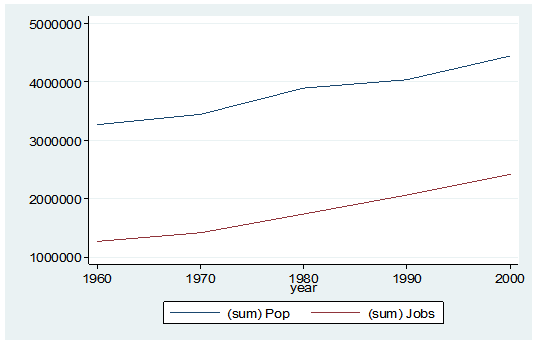
By starting my code with the preserve command it brings my data set back to its original state after providing me with the results I want.
What if I want to look at variables that are in percentages, such as percent of college graduates, mobility and labor force participation rate (lfp)? In this case I don’t want to sum the values because they are in percent.
Calculating the mean would give equal weighting to all counties regardless of size.
Fortunately Stata gives you a very simple way to weight your data based on frequency. You have to determine which variable to use. In this situation I will use the population variable.
Here’s my coding and results:
Preserve
collapse (mean) lfp College Mobil [fw=Pop], by(year)
graph twoway (line lfp year) (line College year) (line Mobil year), ylabel(, angle(horizontal))
list
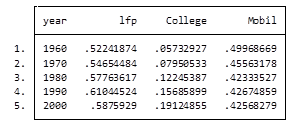
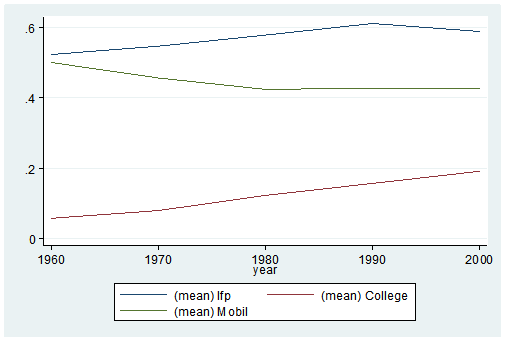
It’s as easy as that. This is one of the five tips and tricks I’ll be discussing during the free Stata webinar on Wednesday, July 29th.
Jeff Meyer is a statistical consultant with The Analysis Factor, a stats mentor for Statistically Speaking membership, and a workshop instructor. Read more about Jeff here.

Hello,
I am using a logit model where the dependent variable is risk of infection (high/low) and independent variables are gender, age, income, and pathogen load. the pathogen load data is not for household level, but represents the pathogen load in waterways for a cluster of households (10-20). so the independent variable is repeated for multiple households. Is there any way to account for low variability in such a variable?
Hello
I have 11 variables which are yes/no answers. I have coded yes = 1 and no= 0. Which stat can I use to retain the 1 and 0 outputs? If I collapse (mean) I get decimals.
Thanks
Hi,
We collapse our data using the “by” statement. As a result, the variables that are being collapsed are summarized in some manner. This is due to reducing the number of observations for the variable in the “by” statement to just one observation. Thus, it’s not possible to keep your 0’s and 1’s as separate observations. The collapse command isn’t the command you want to use.
Jeff
I have dataset in stata and I would like to perform clustered bar graph with error bars. Please help me out
Thanks for detailed explanation! This helped me a lot.
Excellent, thanks for the feedback.
Jeff
Hi! I want to collapse my data by three variables, all of them have many observations repeated, but I’m having problems with the option by (var1 var2 var3) because after the moment I collapse there’s no one just 1 of the observations repeated, there’re a lot
Thanks
Hi Maria,
If you collapsing by 3 categorical variables the number of responses you get will be the number of categories in var1 times the number of categories in var2 times the number of categories in var3. That is the number of unique groups. For each of the unique groups you will get the statistical result that you specify after the collapse command.
Jeff
How do I get back to my original data? I used the preserve command and my data is still intact, but I can’t seem to run code on other variables after collapsing.
Hi, in my do-file I always have the statement for opening the original file. If I want to keep the collapsed data I save that first and then reopen the original.
Hello, I want to generate a line graph to summarise longitudinal data with confidence limits included. Please help me with the syntax.
thanks
Hi Eve,
Here is a link to an example using a bar graph. You would create your code in the same manner but would use a line graph rather than a bar graph. This example shows you how to use the collapse command to generate the standard deviation of your variable of interest and then generate the confidence interval.
https://stats.idre.ucla.edu/stata/faq/how-can-i-make-a-bar-graph-with-error-bars/
Jeff Meyer