You might be surprised to hear that not only can linear regression fit lines between a response variable Y and one or more predictor variables, X, it can fit curves too. There are many ways to do this, but the simplest is by adding a polynomial term.
So what is a polynomial term and how do you know you need one?
The linear parameters in a regression model
A linear regression model has a few key parameters. These include the intercept coefficient, the slope coefficient, and the residual variance.
That intercept defines the height of the regression line. It does so by measuring the height of the line at one specific point: when all X = 0.
The slope defines how much Y differs, on average, for each one unit difference in X. In other words, it measures the constant relationship between X and Y. Yes, there can be multiple Xs and each one has its own slope.
A polynomial term–a quadratic (squared) or cubic (cubed) term turns a linear regression model into a curve.
(more…)
No matter what statistical model you’re running, you need to take the same steps. The order and the specifics of 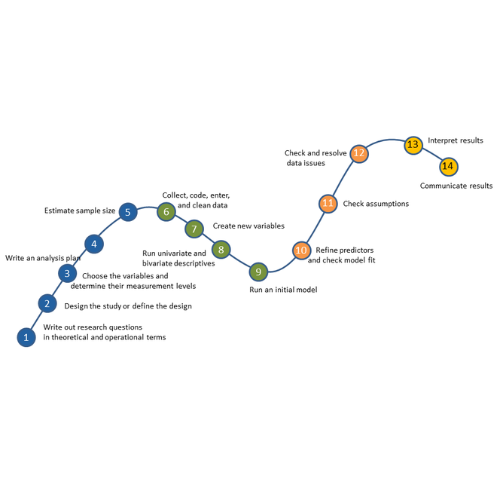 how you do each step will differ depending on the data and the type of model you use.
how you do each step will differ depending on the data and the type of model you use.
These steps are in 4 phases. Most people think of only the third as modeling. But the phases before this one are fundamental to making the modeling go well. It will be much, much easier, more accurate, and more efficient if you don’t skip them.
And there is no point in running the model if you skip the last phase. That’s where you communicate the results.
I’ve found that if I think of them all as part of the analysis, the modeling process is faster, easier, and makes more sense.
Phase 1: Define and Design
In the first five steps of running the model, the object is clarity. You want to make everything as clear as possible to yourself. The clearer things are at this point, the smoother everything will be. (more…)
 When analyzing longitudinal data, do you use regression or structural equation based approaches? There are many types of longitudinal data and different approaches to analyzing them. Two popular approaches are a regression based approach and a structural equation modeling based approach.
When analyzing longitudinal data, do you use regression or structural equation based approaches? There are many types of longitudinal data and different approaches to analyzing them. Two popular approaches are a regression based approach and a structural equation modeling based approach.
(more…)
 Regression is one of the most common analyses in statistics. Most of us learn it in grad school, and we learned it in a specific software. Maybe SPSS, maybe another software package. The thing is, depending on your training and when you did it, there is SO MUCH to know about doing a regression analysis in SPSS.
Regression is one of the most common analyses in statistics. Most of us learn it in grad school, and we learned it in a specific software. Maybe SPSS, maybe another software package. The thing is, depending on your training and when you did it, there is SO MUCH to know about doing a regression analysis in SPSS.
(more…)
If you’ve used much analysis of variance (ANOVA), you’ve probably heard that ANOVA is a special case of linear regression. Unless you’ve seen why, though, that may not make a lot of sense. After all, ANOVA compares means between categories, while regression predicts outcomes with numeric variables. (more…)
(more…)
A very common question is whether it is legitimate to use Likert scale data in parametric statistical procedures that  require interval data, such as Linear Regression, ANOVA, and Factor Analysis.
require interval data, such as Linear Regression, ANOVA, and Factor Analysis.
A typical Likert scale item has 5 to 11 points that indicate the degree of something. For example, it could measure agreement with a statement, such as 1=Strongly Disagree to 5=Strongly Agree. It can be a 1 to 5 scale, 0 to 10, etc. (more…)
