From our last article, you should feel comfortable with the idea of editing and saving data sets in Stata. In this article, we’ll explain how to create new variables in Stata using replace, generate, egen, and clonevar.
The first two commands have a shared help page. Remember you can see this by typing “h gen” or “h replace” into the command window.
replace (changes out data points or variables)
We’ll start with the replace command. Let’s get a fresh version of Stata’s auto dataset
sysuse auto, clear
The replace command allows you to make changes to the values of a variable systematically. Imagine we wanted to change the rep78 variable so all numbers are one higher, and missing values become 1’s:
replace rep78 = rep78 +1
replace rep78 = 1 if rep78 == .
The first command is telling Stata that for each data point in rep78, we replace it with the same data value raised by one.
The second command is telling Stata that for any observation of rep78 with a missing value, replace that value with a 1.
Replace can also change strings!
Imagine that we wanted to make all the Chevrolet cars in this dataset considered to be the same; they’re all just Chevies now. Look at how the following command changes the dataset:
replace make = “Chev.” if strpos(make, “Chev”)
We won’t explain the details of “strpos” and other string command here. For now, we can imagine it as checking for the presence of the string “Chev” in the make variable and returning true in each observation where it exists.
Replace is also the typical command to change just one individual observation.
If we thought the first observation of the trunk variable was wrong and should be a 10 instead, we can type the command:
replace trunk = 10 in 1
We can combine the “if” and “in” options to make certain changes to only part of the dataset. Say I want to make all values of rep78 that are currently set to 1 to become equal to the value of trunk, but only in the first 52 observations. I would type:
replace rep78 = trunk if rep78==1 in 1/52
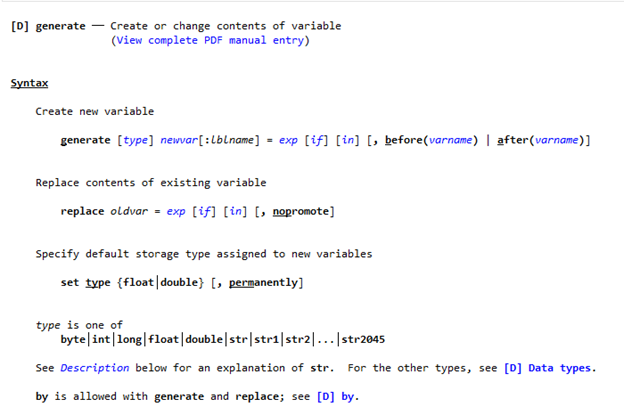
generate (makes new variable)
A close partner to the replace command is the generate command.
These commands mostly have the same abilities. The difference is that generate will leave you with a new variable, whereas replace overrides an existing one.
Suppose we want to make a new variable called “headturn” that will take the value of headroom and multiply it by the value of turn. We can type:
gen headturn = headroom*turn
We get a new variable which, for each observation, holds the value of head multiplied by the value of turn.
Best Practices in Editing Data
It is a really, really good idea to create a copy of a variable before we edit it. That way, you can check for mistakes as you edit.
We might want this variable to be next to the one it’s copying in the data set, which we can do with the “after” option.
Say we want to make a duplicate of the price variable. Generate lets us do this by typing:
gen cprice = price, after(price)
If you go look at the dataset now, you will notice that cprice is right next to price, and has all the same values, but is not identical. It lost all labels, changed from being an int to a float, and lost the formatting that added commas.
To make an exact copy, we would need to use the clonevar command, which is later in this post.
It’s also a good idea to set a variable’s type and label. We can use generate to do this as well. Let’s make a new variable called pricecat that is categorical based on car price.
If we want to give this variable more than 2 values, we will need to use replace and generate together, like so:
generate int pricecat:”Price Category” = price>4000
replace pricecat = 2 if price>5000
replace pricecat = 3 if price>6000
replace pricecat = 4 if price>8000
Enter this code in your Command Window or do-file and look at the resulting variable.
Using generate in conjunction with a logical expression (>,<,==,!= etc) creates a binary variable with a value of 1 in places where the expression is true, and a 0 elsewhere. We told Stata to make this variable have the data type int, and to have a label explaining the meaning.
You might consider turning this variable into a factor. Later in this series we’ll learn how to work with factors by using encode and decode.
Next, imagine we wanted a variable that takes on the maximum of two other variables. To get a variable that takes the largest value of length and displacement, enter the following code:
gen higher = rowmax(length displacement)
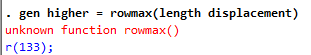
Even though rowmax is a valid function in Stata, it can’t be used with generate. It needs something with an extension to generate. Something like the egen command!
egen (makes a new variable with more options)
For complicated expressions (like making a new variable that takes the maximum value of two other variables, using functions like mean), we sometimes may need to use the egen command.
egen has way more options available than generate. You can make variables based on just about any rule you could imagine. Try typing
h egen
And explore the functions and options on the help page. We can’t look at every function here, so keep this page in mind when you need to figure out how to make a complex variable.
Let’s try the code that just failed us, but this time replace generate with egen:
egen higher = rowmax(length displacement)
In observations with a higher length, the variable takes the length value; in observations with higher displacement, it takes the displacement value.
egen can also be used with the cut function to create something like the pricecat variable all in one command.
egen int pricecat2 = cut(price), at(0 4000 5000 6000 8000 20000) icodes
This command creates an integer called pricecat2 which divides into 5 groups (0-4,000), (4,000-5,000), (5,000-6,000), (6,000,8,000), (8,000-20,000).
The icodes option makes it so we get the values 0,1,2,3,4, rather than values based on the cuts.
Let’s use this new categorical variable to make something else new! Imagine we want a variable that, for each price group, tells us the mean weight within that group.
bysort pricecat2: egen avggroupweight = mean(weight)
The bysort command tells us: for everything after the colon, do it separately for each value of the variable we’re sorting by.
So for each value of pricecat2, all observations in that group show the mean weight within that group.
clonevar (makes exact copy of variable with its label)
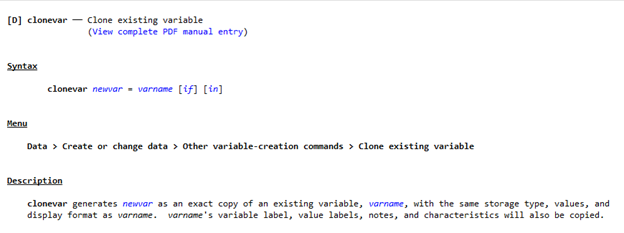
Earlier we saw that using generate to make a copy of a variable does not make an exact copy. Generated copies lose their labels, might have their type recast, and lose formatting information.
To make an exact copy, we can use the command clonevar.
Let’s demonstrate clonevar with a fresh copy of the auto data. Type
sysuse auto, clear
clonevar origin = foreign
This creates a variable called origin which is an exact copy of foreign in all ways but name. All values, formatting, and labels match.
We can also make a partial copy by using if or in
clonevar partprice = price if length>200
This creates a variable that has the same labels and data type as price, but only includes observations where length is greater than 200 inches. The rest become missing values.
Whew! That was a lot of new variables. We’re done for now, and you should be confident with using Stata to make your own variables. Join us in the next blog post where we will talk about using Stata to change numeric variables.
by James Harrod
About the Author: James Harrod interned at The Analysis Factor in the summer of 2023. He plans to continue into a career as an actuary, and hopes to continue finding interesting ways of educating people about statistics. James is well-versed in R and Stata programming and enjoys teaching the intuition behind common statistical methods. James is a 2023 graduate of the University of Rochester with bachelor’s degrees in Statistics and Economics.

Leave a Reply