I mentioned in my last post that R Commander can do a LOT of data manipulation, data analyses, and graphs in R without you ever having to program anything.
I mentioned in my last post that R Commander can do a LOT of data manipulation, data analyses, and graphs in R without you ever having to program anything.
Here I want to give you some examples, so you can see how truly useful this is.
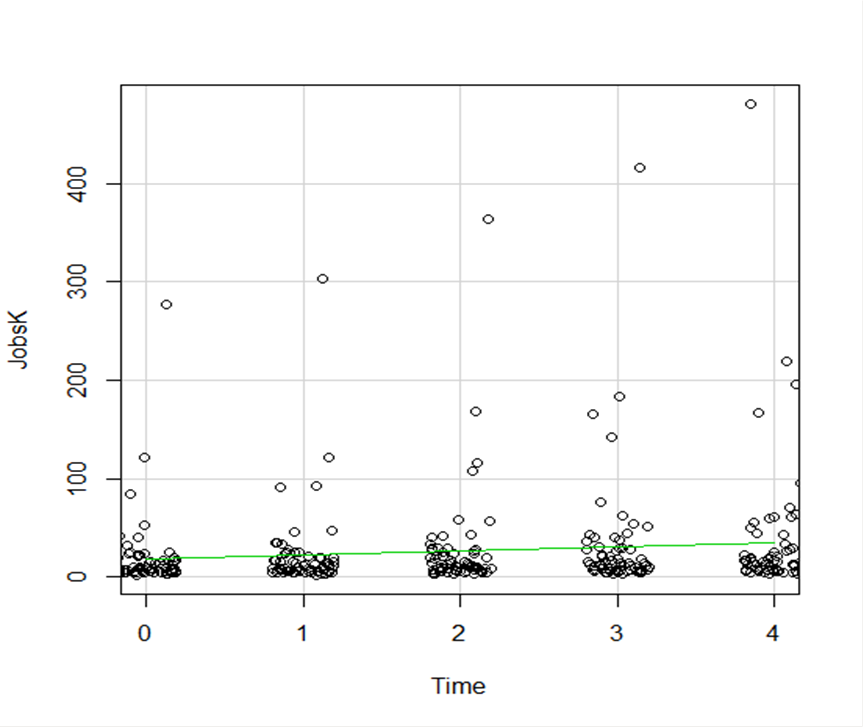
Let’s start with a simple scatter plot between Time and the number of Jobs (in thousands) in 67 counties. Time is measured in decades since 1960.
The green line is the best fit linear regression line.
This wasn’t the default in R Commander (I actually had to remove a few things to get to this), but it’s a useful way to start out.
A few ways we can easily customize this graph:
Jittering
We see here a common issue in scatter plots–because the X values are discrete, the points are all on top of each other.
It’s difficult to tell just how many points there are at the bottom of the graph–it’s just a mass of black.
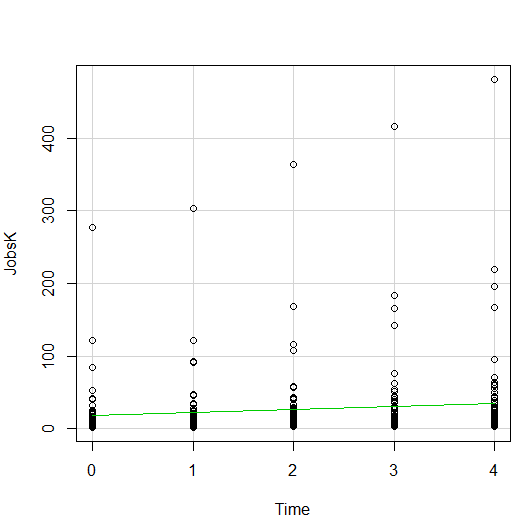
One great way to solve this is by jittering the points.
All this means is that instead of putting identical points right on top of each other, we move it slightly, randomly, in either one or both directions. In this example, I jittered only horizontally:
So while the points aren’t graphed exactly where they are, we can see the trends and we can now see how many points there are in each decade.
How hard is this to do in R Commander? One click:
Regression Lines by Group
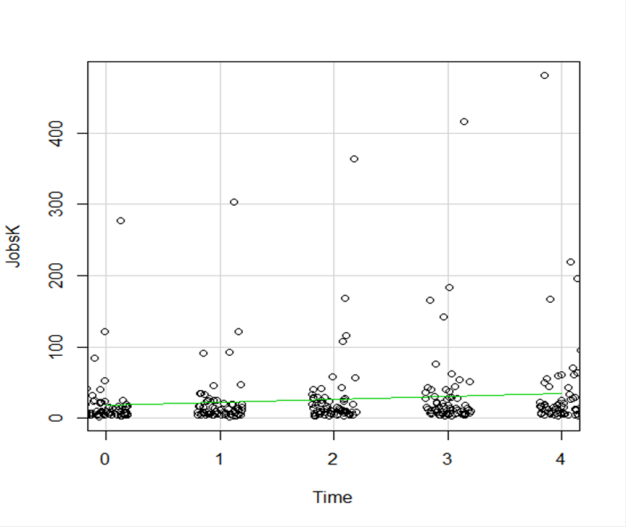
Another useful change to a scatter plot is to add a separate regression line to the graph based on some sort of factor in the data set.
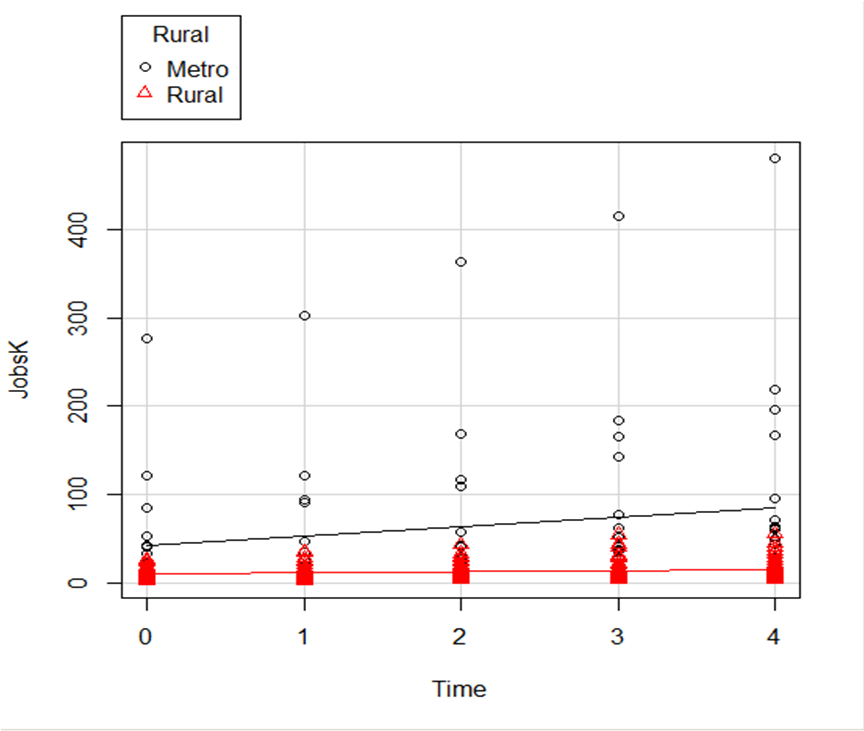
In this example, the observations are measured for counties and each county is classified as being either Rural or Metropolitan.
If we’d like to see if the growth in jobs over time is different in Rural and Metropolitan counties, we need a separate line for each group.
In R Commander we can do this quite easily. Not only do we get two regression lines, but each point is clearly designated as being from either a Rural or Metropolitan county through its color and shape.
It’s quite clear that not only was there more growth in the number of jobs in Metro counties, there was almost no change at all in the Rural counties.
 And once again, how difficult is this? This time, two clicks.
And once again, how difficult is this? This time, two clicks.
There are quite a few modifications you can make just using the buttons, but of course, R Commander doesn’t do everything.
For example, I could not figure out how to change those red triangles to green rectangles through the menus.
But that’s the best part about R Commander. It works very much like the Paste button in SPSS.
Meaning, it creates the code for you. So I can take the code it created, then edit it to get my graph looking the way I want.
I don’t have to memorize which command creates a scatter plot.
I don’t have to memorize how to pull my SPSS data into R or tell R that Rural is a factor. I can do all that through R Commander, then just look up the option to change the color and shape of the red triangles.
I received a question recently about R Commander, a free R package.
R Commander overlays a menu-based interface to R, so just like SPSS or JMP, you can run analyses using menus. Nice, huh?
The question was whether R Commander does everything R does, or just a small subset.
Unfortunately, R Commander can’t do everything R does. Not even close.
But it does a lot. More than just the basics.
So I thought I would show you some of the things R Commander can do entirely through menus–no programming required, just so you can see just how unbelievably useful it is.
Since R commander is a free R package, it can be installed easily through R! Just type install.packages("Rcmdr") in the command line the first time you use it, then type library("Rcmdr") each time you want to launch the menus.
Data Sets and Variables
Import data sets from other software:
- SPSS
- Stata
- Excel
- Minitab
- Text
- SAS Xport
Define Numerical Variables as categorical and label the values
Open the data sets that come with R packages
Merge Data Sets
Edit and show the data in a data spreadsheet
Personally, I think that if this was all R Commander did, it would be incredibly useful. These are the types of things I just cannot remember all the commands for, since I just don’t use R often enough.
Data Analysis
Yes, R Commander does many of the simple statistical tests you’d expect:
- Chi-square tests
- Paired and Independent Samples t-tests
- Tests of Proportions
- Common nonparametrics, like Friedman, Wilcoxon, and Kruskal-Wallis tests
- One-way ANOVA and simple linear regression
What is surprising though, is how many higher-level statistics and models it runs:
- Hierarchical and K-Means Cluster analysis (with 7 linkage methods and 4 options of distance measures)
- Principal Components and Factor Analysis
- Linear Regression (with model selection, influence statistics, and multicollinearity diagnostic options, among others)
- Logistic regression for binary, ordinal, and multinomial responses
- Generalized linear models, including Gamma and Poisson models
In other words–you can use R Commander to run in R most of the analyses that most researchers need.
Graphs
A sample of the types of graphs R Commander creates in R without you having to write any code:
- QQ Plots
- Scatter plots
- Histograms
- Box Plots
- Bar Charts
The nice part is that it does not only do simple versions of these plots. You can, for example, add regression lines to a scatter plot or run histograms by a grouping factor.
If you’re ready to get started practicing, click here to learn about making scatterplots in R commander, or click here to learn how to use R commander to sample from a uniform distribution.
 Latent Class Analysis is a method for finding and measuring unobserved latent subgroups in a population based on responses to a set of observed categorical variables.
Latent Class Analysis is a method for finding and measuring unobserved latent subgroups in a population based on responses to a set of observed categorical variables.
This webinar will present an overview and an example of how latent class analysis works to find subgroups, how to interpret the output, the steps involved in running it. We will discuss extensions and uses of the latent classes in other analyses and similarities and differences with related techniques.
Note: This training is an exclusive benefit to members of the Statistically Speaking Membership Program and part of the Stat’s Amore Trainings Series. Each Stat’s Amore Training is approximately 90 minutes long.
(more…)
This free, one-hour webinar is part of our regular Craft of Statistical Analysis series. In it, we will introduce and demonstrate two of the core concepts of mixed modeling—the random intercept and the random slope.
Most scientific fields now recognize the extraordinary usefulness of mixed models, but they’re a tough nut to crack for someone who didn’t receive training in their methodology.
But it turns out that mixed models are actually an extension of linear models. If you have a good foundation in linear models, the extension to mixed models is more of a step than a leap. (Okay, a large step, but still).
You’ll learn what random intercepts and slopes mean, what they do, and how to decide if one or both are needed. It’s the first step in understanding mixed modeling.
Date: Friday, August 21, 2015
Time: 12pm EDT (New York time)
Cost: Free
***Note: This webinar has already taken place. Sign up below to get access to the video recording of the webinar.
Whenever we run an analysis of variance or run a regression one of the first things we do is look at the p-value of our predictor variables to determine whether
they are statistically significant. When the variable is statistically significant, did you ever stop and ask yourself how significant it is? (more…)
Why is it we can model non-linear effects in linear regression?
What the heck does it mean for a model to be “linear in the parameters?” (more…)