No matter what statistical model you’re running, you need to take the same steps. The order and the specifics of 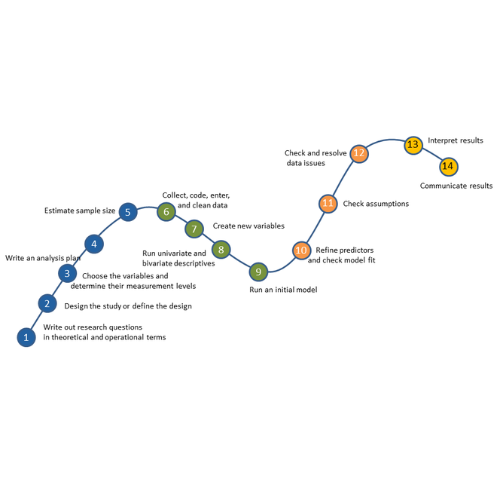 how you do each step will differ depending on the data and the type of model you use.
how you do each step will differ depending on the data and the type of model you use.
These steps are in 4 phases. Most people think of only the third as modeling. But the phases before this one are fundamental to making the modeling go well. It will be much, much easier, more accurate, and more efficient if you don’t skip them.
And there is no point in running the model if you skip the last phase. That’s where you communicate the results.
I’ve found that if I think of them all as part of the analysis, the modeling process is faster, easier, and makes more sense.
Phase 1: Define and Design
In the first five steps of running the model, the object is clarity. You want to make everything as clear as possible to yourself. The clearer things are at this point, the smoother everything will be. (more…)
When we think about model assumptions, we tend to focus on assumptions like independence, normality, and constant variance. The other big assumption, which is harder to see or test, is that there is no specification error. The assumption of linearity is part of this, but it’s actually a bigger assumption.
What is this assumption of no specification error? (more…)

Before you can write a data analysis plan, you have to choose the best statistical test or model. You have to integrate a lot of information about your research question, your design, your variables, and the data itself.
(more…)
There is a bit of art and experience to model building. You need to build a model to answer your research question but how do you build a statistical model when there are no instructions in the box?
Should you start with all your predictors or look at each one separately? Do you always take out non-significant variables and do you always leave in significant ones?
(more…)