If you have run mixed models much at all, you have undoubtedly been haunted by some version of this very obtuse warning: “The 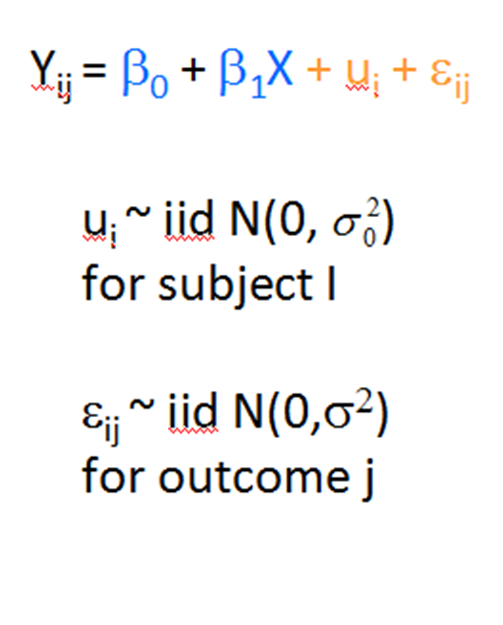 Hessian (or G or D) Matrix is not positive definite. Convergence has stopped.”
Hessian (or G or D) Matrix is not positive definite. Convergence has stopped.”
Or “The Model has not Converged. Parameter Estimates from the last iteration are displayed.”
What on earth does that mean?
Let’s start with some background. If you’ve never taken matrix algebra, these concepts can be overwhelming. So I’m going to simplify them into the basic issues that arise for you, the data analyst. If you’d like a more mathematical and thorough answer, see one of the references.
The D Matrix (called G by SAS) is the matrix of the variances and covariances of the random effects. The variances are listed on the diagonal of the matrix and the covariances are on the off-diagonal. So a model with a random intercept and random slope (two random effects) would have a 2×2 D matrix. The variances of the intercept and slope would be on the diagonal and their covariance would be in the one non-diagonal place.
Without getting into the math, a matrix can only be positive definite if the entries on the main diagonal are non-zero and positive. This makes sense for a D matrix, because we definitely want variances to be positive (remember variances are squared values).
The Hessian Matrix is based on the D Matrix, and is used to compute the standard errors of the covariance parameters. The iterative algorithms that estimate these parameters are pretty complex, and they get stuck if the Hessian Matrix doesn’t have those same positive diagonal entries.
The result is you can’t trust the reported results, no matter how much they look like the results you usually get. The software was unable to come up with stable estimates. It means that for some reason, the model you specified can’t be estimated properly with your data. Whatever you do, don’t ignore this warning.
As cryptic as it is, it’s important.
What do I do about it?
One simple solution is to check the scaling of your predictor variables. If they’re on vastly different scales, the model might have trouble calculating variances. So if they differ by an order of magnitude (or more), you may need to simply change the scaling of a predictor.
Another thing to check is the variances. When this warning appears, you will often notice some variance estimates are either 0 or have no estimate or no standard errors at all. (In my experience, this is almost always the cause).
This is important information. If the best estimate for a variance is 0, it means there really isn’t any variation in the data for that effect. For example, perhaps the slopes don’t really vary across individuals, and a random intercept captures all the variation.
When this happens, you need to respecify the random parts of the model. It may mean you need to remove a random effect. Sometimes even when a random effect ought to be included because of the design, you can’t. There just isn’t any variation in the data. Or you may need to use a simpler covariance structure with fewer unique parameters.
An Example
Here’s an example that came up recently in consulting. The researcher surveyed parents about their kids’ experience in school. The parents were sampled within classrooms, and the design indicated including a random intercept for class. This accounts for the fact that parents of kids in the same class may be more similar to each other than would be the case in a simple random sample.
After all, their kids are having similar experiences in school. If responses are more similar within a class, they’re more varied across classes. We’d want to estimate the variance among classrooms.
But in this data set it wasn’t.
It turned out that the responses of parents from the same classroom were not any more similar than parents from different classrooms. The variance for classroom was 0. The model was unable to uniquely estimate any variation from classroom to classroom, above and beyond the residual variance from parent to parent.
Another Solution
Another option, if the design and your hypotheses allow it, is to run a marginal (aka population-averaged) model instead of a mixed model. Marginal models don’t actually contain random effects. But they will account for correlations within multiple responses by individuals. And they have less strict mathematical requirements.
You can run marginal models in both SAS and SPSS by using a Repeated statement instead of a Random statement in Mixed. In R, use gls() from the lme4 package.
For more information and more options, read:
West, B., Welch, K, and Galecki, A. (2007). Linear Mixed Models: A Practical Guide Using Statistical Software. Chapman & Hall.
Long, J.S. (1997). Regression models for categorical and limited dependent variables. Sage Publications.
Gill, J. & King, G. (2004). SOCIOLOGICAL METHODS & RESEARCH, (33)1, 54-87. http://gking.harvard.edu/files/help.pdf

I’m having issues on working with Hessian Modelling in Economics.
please kindly help out
Hello, i am trying to run a univaraiate growth curve model for 3 waves of data collected for scores on a behaviour test for students age 4 to 6 years (at T1). There are missing data especially at T3 (n=300 at T1, n=230 at T2, n=140 at T3). In SPSS I used TIME=INDEX 1, 2 and 3 but want to use age instead since the study is about developmental growth. If I use AGE as the time metric I get the dreaded warning about model nonconvergence and iterations terminated. PLEASE help me. How to I handle AGE as TIME? I would be extremely grateful for ANY advice you can provide.
Hi Karen,
I’m running a multiplciative model to detect drug-drug interaction in spontaneous databases and I often (too often) get the warning.
One example is the following, where n is the first drug, d the second and cve is the event of interest:
data tt;
input n d cve freq;
datalines;
1 1 1 5
1 0 1 929
0 1 1 23
0 0 1 20444
1 1 0 113
1 0 0 27007
0 1 0 4350
0 0 0 3696553
;
run;
proc sort data=work.tt out=work.test;
by d n;
run;
proc transpose data=work.test
out=work.aaa
prefix=column
name=source
label=label
;
by d n;
id cve;
var freq;
run; quit;
proc sql;
create table work.aaaa as
select t1.d,
t1.n,
(t1.column1) as y,
(t1.column1+t1.column0) as tot
from work.aaa t1;
quit;
proc genmod data=work.aaaa
plots(only)=all
;
class n d
;
freq tot;
model y/tot = n d n*d
/
link=log
;
run; quit;
Could you please help me?
Many thanks!
Hello Karen,
I am running a mixed model to estimate the genetic correlations between two traits in SAS. This is the model I am using :
proc mixed data= mmlw34 covtest asycov ;
class trait family Block sample;
model y = trait block;
random trait /type=un sub=family g gcorr;
repeated /type=un subject=family*sample r rcorr;
ods output CovParms=_varcomp AsyCov=_cov ;
run;
In my experiment I have 15 open-pollinated families (“family”) of Pinus sylvestris in a common garden trial with 8 plants per family. The variable “trait” has two values: 1 and 2 for the two studied traits. The dependent variable “y” contains the individual values for each trait. When I run the model I obtain this message “Estimated G matrix is not positive definite.”. I obtain the covariance parameters, the G matrix, the G correlation matrix and the asymptotic covariance matrix. However, when I use the covariance of traits and the variance of each trait to estimate the genetic correlation, r > 1.0, what it is impossible. I have checked the covariance parameters and they are positive and not near 0. Only the covariance between traits is a negative, but I do not think that is the reason why I get the warning message. Since I cannot modify the model to calculate the g correlations, I do not know what else I can do…Do you have any thought?
Thanks a lot!
Jose
Hi Karen –
I am running a model with only categorical variables. Most of the variables are binary, however when I add a variable with more then two levels I get the error statement concerning the Generalized Hessian Matrix (I believe it says it is not positive). Any idea why that would be the case? Also, I am using proc Genmod.
Thanks, Jenny
Hi Jenny,
Even if I’m working with the data, the cause of this isn’t always clear. I would start with checking for complete separation.
Hi there,
I’m getting a Hessian issue I still haven’t been able to resolve. Typically when I get these issues I realize after the fact it’s an easy fix– a random effect that I needed to remove, for instance, in a three level model. But this time I can’t figure it out. Is it because the mean of my DV is close to 0 (it’s a difference score)? Why does the Hessian problem go away when I add an additional control variable to my model? any ideas?
Hi A,
These are difficult to diagnose without getting my hands dirty, but yes, it’s possible that it’s because the DV is close to 0, especially if there is not a lot of variance.
I once had a hessian problem go away when I divided the DV by 1000. The variances were just too big.
Hi Karen,
Thanks for this information, I had a lot of difficulty finding anything about this Hessian matrix warning. I get this problem coming up a lot in my analyses and I’m paritcularly surprised as it comes up when I use identidy as a random factor, as some of my data set includes measurements from more than one individual (and its not appropriate to average them). If I don’t include it, I worry I will be criticised for pseudoreplication. If I try a population model, do I use identity as the repeated statement even though not all individuals are used more than once?
Also, when you do have a random effect but it is not significant, should you then remove and re-run the anlaysis or still leave it in?
Any help would be great.
Thanks,
Leanne
Hi Leanne,
If some individuals have only one measurement, that could be the cause of the Hessian problems. There’s no residual variation around the mean for that subject b/c the one data point is the mean. It’s really hard to diagnose that kind of thing without digging into the data, though.
To run a population averaged model, you would have to define individual as the subject and specify the covariance structure for each subject’s multiple measurements. Be careful here, as it can make a big difference.
And the significance tests for the random effects are generally considered pretty inaccurate tests. I don’t even look at them. You’re better off computing the intraclass correlation.
And fyi, West, Welch, and Galecki’s Linear Mixed Models book has a nice explanation about the Hessian matrix warning, if you’d like more info.
Best,
Karen