new blog post: Member Training: The Dark Side of Data Science

Previous Posts
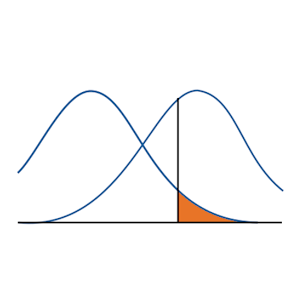
Most of the p-values we calculate are based on an assumption that our test statistic meets some distribution. These distributions are generally a good way to calculate p-values as long as assumptions are met. But it’s not the only way to calculate a p-value. Rather than come up with a theoretical probability based on a distribution, exact tests calculate a p-value empirically. The simplest (and most common) exact test is a Fisher’s exact for a 2x2 table. Remember calculating empirical probabilities from your intro stats course? All those red and white balls in urns? The calculation of empirical probability starts with the number of all the possible outcomes.
How do you choose between Poisson and negative binomial models for discrete count outcomes? One key criterion is the relative value of the variance to the mean after accounting for the effect of the predictors. A previous article discussed the concept of a variance that is larger than the model assumes: overdispersion. (Underdispersion is also […]
I recently held a free webinar in our The Craft of Statistical Analysis program about Binary, Ordinal, and Nominal Logistic Regression. It was a record crowd and we didn’t get through everyone’s questions, so I’m answering some here on the site. They’re grouped by topic, and you will probably get more out of it if […]
We previously examined why a linear regression and negative binomial regression were not viable models for predicting the expected length of stay in the hospital for people with the flu. A linear regression model was not appropriate because our outcome variable, length of stay, was discrete and not continuous. A negative binomial model wasn’t the […]
Transformations don’t always help, but when they do, they can improve your linear regression model in several ways simultaneously. They can help you better meet the linear regression assumptions of normality and homoscedascity (i.e., equal variances). They also can help avoid some of the artifacts caused by boundary limits in your dependent variable -- and sometimes even remove a difficult-to-interpret interaction. In this webinar, we will review the assumptions of the linear regression model and explain when to consider a transformation of the dependent variable or independent variable.
Imagine this scenario: This year’s flu strain is very vigorous. The number of people checking in at hospitals is rapidly increasing. Hospitals are desperate to know if they have enough beds to handle those who need their help. You have been asked to analyze a previous year’s hospitalization length of stay by people with the […]
In this video I will answer a question from a recent webinar Random Intercept and Random Slope Models. We are answering questions here because we had over 500 people live on the webinar so we didn't have time to get through all the questions.
In this video I will answer a question from a recent webinar Random Intercept and Random Slope Models. We are answering questions here because we had over 500 people live on the webinar so we didn't have time to get through all the questions.
Interpreting regression coefficients can be tricky. Especially when there are interactions in the model. Or categorical predictors. (Or worse – both.) But there is a secret weapon that can help you make sense of your regression results: marginal means. They’re not the same as descriptive stats. They aren’t usually included by default in our output. And they sometimes go by the name LS or Least-Square means. And they’re your new best friend. So what are these mysterious, helpful creatures? What do they tell us, really? And how can we use them?
Question: Can you talk more about categorical and repeated Time? If I have 5 waves at ages 0, 1 year, 3 years, 5 years, and 9 years, would that be categorical or repeated? Does mixed account for different spacing in time? Mixed models can account for different spacing in time and you’re right, it […]
 stat skill-building compass
stat skill-building compass