new blog post: Member Training: Dummy and Effect Coding
Previous Posts
On my first assignment using Stata, I think I spent four or five hours trying to present my output in a “professional” form. The most creative method I heard about in class the next day was to copy the contents into Excel, create page breaks and then copy into Word. SPSS makes it so easy to copy tables and graphs into another document. Why can’t Stata be easy? Anyone who has used Stata has gone through this and many of you still are. No worries, help is on the way!..
We've already discussed using macros in Stata to simplify and shorten code. Another great tool in your coding tool belt is loops. Loops allow you to run the same command for several variables at one time without having to write separate code for each variable. This discussion could go on for pages and pages because there is much you can do with a loop...
We finished the last blog with the confusing coding of: local continuous educatexper wage age foreachvar in `continuous'{ graph box `var', saving(`var',replace) } I admit it looks like a foreign language. Let me explain how simple it is to understand..
Most statistical software packages use a spreadsheet format for viewing the data. This helps you get a feeling for what you will be working with, especially if the data set is small. But what if your data set contains numerous variables and hundreds or thousands of observations? There is no way you can get warm and fuzzy by browsing through a large data set. To help you get a good feel for your data you will need toutilize your software’s command or syntax editor to write a series of code for reviewing your data. Sounds complicated...
ROC Curves are incredibly useful in evaluating any model or process that predicts group membership of individuals. ROC stands for Receiver Operating Characteristic. This strange name goes back to its original use of assessing the accuracy of sonar readings. Any ROC can tell you how well a process or model distinguishes between true and false positives and negatives.
So I was glad that SPSS became an option for generalized linear mixed models. But that Model Viewer had led me to nearly give up that option. It's that annoying. (Google it if you're curious about the hate for the Model Viewer). Anyway, there is now a way to get rid of it.
How should I build my model? I get this question a lot, and it's difficult to answer at first glance--it depends too much on your particular situation. There are really three parts to the approach to building a model: the strategy, the technique to implement that strategy, and the decision criteria used within the technique.
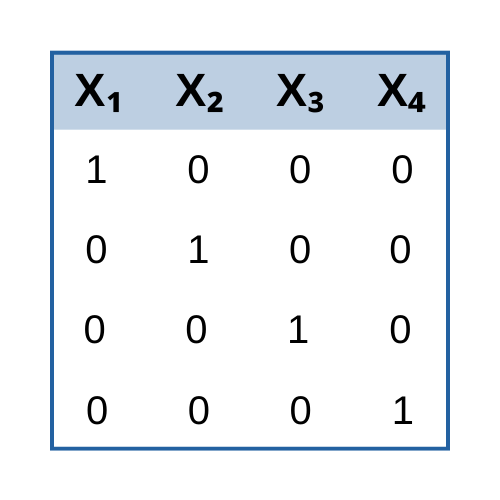
Like many people with graduate degrees, I have used a number of statistical software packages over the years. Through work and school I have used Eviews, SAS, SPSS, R and Stata. Some were more difficult to use than others but if you used them often enough you would become proficient to take on the task at hand (though some packages required greater usage of George Carlin’s 7 dirty words). There was always one caveat which determined which package I used...
If you have worked on or know of a paper that used mixed models, please give us the reference in the comments. Links to online versions are great too, if you have one. Trust me, many people in your field are looking for an example and will be happy to cite it.
Repeated measures ANOVA is the approach most of us learned in stats classes, and it works very well in certain designs. But it’s a bit limited in what it can do. Sometimes trying to fit a data set into a repeated measures ANOVA requires too much data gymnastics—averaging across repetitions or pretending a continuous predictor isn’t really.
 stat skill-building compass
stat skill-building compass