One activity in data analysis that can seem impossible is the quest to find the right analysis. I applaud the conscientiousness and integrity that  underlies this quest.
underlies this quest.
The problem: in many data situations there isn’t one right analysis.
One activity in data analysis that can seem impossible is the quest to find the right analysis. I applaud the conscientiousness and integrity that underlies this quest.
The problem: in many data situations there isn’t one right analysis.
by Jeff Meyer
As mentioned in a previous post, there is a significant difference between truncated and censored data.
Truncated data eliminates observations from an analysis based on a maximum and/or minimum value for a variable.
Censored data has limits on the maximum and/or minimum value for a variable but includes all observations in the analysis.
As a result, the models for analysis of these data are different. (more…)
At The Analysis Factor, we are on a mission to help researchers improve their statistical skills so they can do amazing research.
We all tend to think of “Statistical Analysis” as one big skill, but it’s not.
Over the years of training, coaching, and mentoring data analysts at all stages, I’ve realized there are four fundamental stages of statistical skill:


Stage 3: Extensions of Linear Models

Stage 4: Advanced Models
There is also a stage beyond these where the mathematical statisticians dwell. But that stage is required for such a tiny fraction of data analysis projects, we’re going to ignore that one for now.
If you try to master the skill of “statistical analysis” as a whole, it’s going to be overwhelming.
And honestly, you’ll never finish. It’s too big of a field.
But if you can work through these stages, you’ll find you can learn and do just about any statistical analysis you need to. (more…)
Most of the p-values we calculate are based on an assumption that our test statistic meets some distribution. Common examples include t distributions, F distributions, 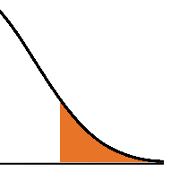 and chi-square distributions.
and chi-square distributions.
These distributions are generally a good way to calculate p-values as long as assumptions are met.
But it’s not the only way to calculate a p-value.
Rather than come up with a theoretical probability based on a distribution, exact tests calculate a p-value empirically.
The simplest (and most common) exact test is a Fisher’s exact for a 2×2 table.
Remember calculating empirical probabilities from your intro stats course? All those red and white balls in urns? (more…)
Outliers are one of those realities of data analysis that no one can avoid.
Those pesky extreme values cause biased parameter estimates, non-normality in otherwise beautifully normal variables, and inflated variances.
Everyone agrees that outliers cause trouble with parametric analyses. But not everyone agrees that they’re always a problem, or what to do about them even if they are.
Sometimes a non-parametric or robust alternative is available.
And sometimes not.
There are a number of approaches in statistical analysis for dealing with outliers and the problems they create.
It’s common for committee members or Reviewer #2 to have Very. Strong. Opinions. that there is one and only one good approach.
Two approaches that I’ve commonly seen are:
1) delete outliers from the sample, or
2) winsorize them (i.e., replace the outlier value with one that is less extreme).
The problem with both of these “solutions” is that they also cause problems — biased parameter estimates and underweighted or eliminated valid values. (more…)
You may have heard of McNemar tests as a repeated measures version of a chi-square test of independence. This is basically true, and I wanted to show you how these two tests differ and what exactly, each one is testing.
First of all, although Chi-Square tests can be used for larger tables, McNemar tests can only be used for a 2×2 table. So we’re going to restrict the comparison to 2×2 tables. (more…)