by Maike Rahn, PhD
Rotations
An important feature of factor analysis is that the axes of the factors can be rotated within the multidimensional variable space. What does that mean?
Here is, in simple terms, what a factor analysis program does while determining the best fit between the variables and the latent factors: (more…)
Two methods for dealing with missing data, vast improvements over traditional approaches, have become available in mainstream statistical software in the last few years.
Both of the methods discussed here require that the data are missing at random–not related to the missing values. If this assumption holds, resulting estimates (i.e., regression coefficients and standard errors) will be unbiased with no loss of power.
The first method is Multiple Imputation (MI). Just like the old-fashioned imputation (more…)
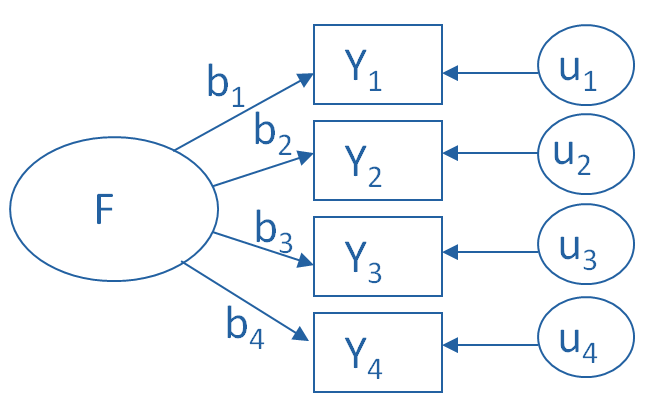
Why use factor analysis?
Factor analysis is a useful tool for investigating variable relationships for complex concepts such as socioeconomic status, dietary patterns, or 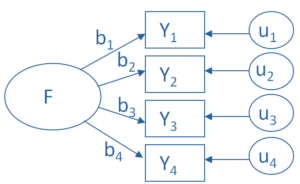 psychological scales.
psychological scales.
It allows researchers to investigate concepts they cannot measure directly. It does this by using a large number of variables to esimate a few interpretable underlying factors.
What is a factor?
The key concept of factor analysis is that multiple observed variables have similar patterns of responses because they are all associated with a latent variable (i.e. not directly measured). (more…)
Like some of the other terms in our list–level and beta–GLM has two different meanings.
It’s a little different than the others, though, because it’s an abbreviation for two different terms:
General Linear Model and Generalized Linear Model.
It’s extra confusing because their names are so similar on top of having the same abbreviation.
And, oh yeah, Generalized Linear Models are an extension of General Linear Models.
And neither should be confused with Generalized Linear Mixed Models, abbreviated GLMM.
Naturally. (more…)
Before you run a Cronbach’s alpha or factor analysis on scale items, it’s generally a good idea to reverse code items that are negatively worded so that a high value indicates the same type of response on every item.
So for example let’s say you have 20 items each on a 1 to 7 scale. For most items, a 7 may indicate a positive attitude toward some issue, but for a few items, a 1 indicates a positive attitude.
I want to show you a very quick and easy way to reverse code them using a single command line. This works in any software. (more…)
If you’ve ever done any sort of repeated measures analysis or mixed models, you’ve probably heard of the unstructured covariance matrix. They can be extremely useful, but they can also blow up a model if not used appropriately. In this article I will investigate some situations when they work well and some when they don’t work at all.
The Unstructured Covariance Matrix
 The easiest to understand, but most complex to estimate, type of covariance matrix is called an unstructured matrix. Unstructured means you’re not imposing any constraints on the values. For example, if we had a good theoretical justification that all variances were equal, we could impose that constraint and have to only estimate one variance value for every variance in the table.
The easiest to understand, but most complex to estimate, type of covariance matrix is called an unstructured matrix. Unstructured means you’re not imposing any constraints on the values. For example, if we had a good theoretical justification that all variances were equal, we could impose that constraint and have to only estimate one variance value for every variance in the table.
But in an unstructured covariance matrix there are no constraints. Each (more…)