The first real data set I ever analyzed was from my senior honors thesis as an undergraduate psychology major. I had taken both intro stats and an ANOVA class, and I applied all my new skills with gusto, analyzing every which way.
It wasn’t too many years into graduate school that I realized that these data analyses were a bit haphazard. (Okay, a LOT). And honestly, not at all well thought out.
A few decades of data analysis experience later, I realized that’s just a symptom of being an inexperienced data analyst.
But even experienced data analysts can get off track. It’s especially easy with large data sets with many variables. It’s just so tempting to try one thing, then another, and pretty soon you’ve spent weeks getting nowhere.
The lesson? Make a plan.
Make a Plan
According to Frank Scarpaci, owner of Project Designworks, there is a
“1:10:100 Rule:
Every dollar spent on planning and preparation saves $10 on
project work or $100 on fixing problems after the project is done.”
I’m pretty sure that ratio holds for not just money, but time and frustration. I mean, you’d rather spend an hour now planning the analysis than two weeks redoing it after reviewers rip it to shreds, right?
The best time to plan the analysis is before collecting data.
This prevents those situations where you can’t really answer your research question because you needed another variable or you should have measured something differently.
I’ve seen a much more common situation though, in years of helping people figure out the best way to analyze their data after they’ve collected it. Their lack of a solid plan made the analysis more difficult than it had to be.
And that’s why even if you don’t have a grant application forcing you to make an analysis plan, you should make one!
How do you plan it?
There are many parts to a statistical analysis plan, but usually the hardest part is choosing the right inferential analysis. This is something we help people with, so if you’re struggling, we’re here to help.
I find a great basis for this part of the statistical analysis plan comes from an old article by Daryl Bem about writing journal articles. There is some out of date and bad advice in there about p-hacking, but the section on writing results is great.
The most helpful part for planning is the section, “Presenting the Findings”. This section outlines 7 steps for reporting each finding. For planning purposes, I condense these into three:
- State the conceptual hypothesis you are asking
- Restate this hypothesis in the terms of the variables that measure the concept
- List the statistical test or method that will answer this question
Simply repeat these three steps for all hypotheses the study is set up to answer. Start with the most general and important, and work down from there.
The Research Question is Central
I think of choosing the analysis and writing the plan as part of the steps of running an analysis. It’s the first phase of the Data Analysis Pathway.
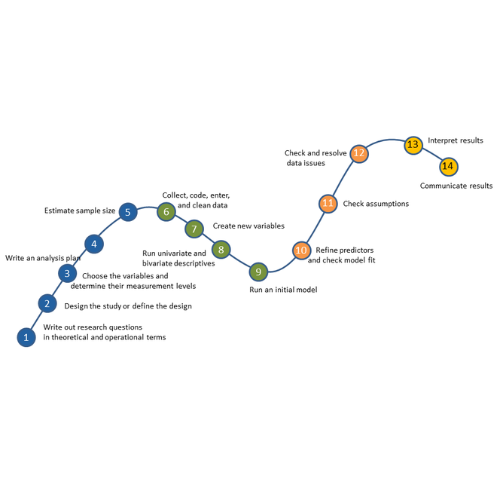
You may have noticed that the very first step is the conceptual hypothesis, or in looser terms, the research question. Every analysis you run should ultimately move you toward answering the research question.
Write down your research questions and tape it to the wall near your computer. Or right to your laptop.
There may be additional analyses that support the main one, and you may or may not be able to plan for them. But they should still serve the overall purpose of answering the research question.
For example, always plan on running univariate and bivariate descriptives and graphs to get a sense of your variables and their most basic relationships before you do much else (Step 8 in the pathway).
Likewise, If you know you will need to run a factor analysis to create an index variable or deal with inevitable missing data, plan for those too.
Even the best plans, though, are guidelines. Surprises do come up (both good and bad), and you will probably have to adjust it as you go along. But don’t let that stop you from planning.
Planning a statistical analysis when you don’t know which tests answer the research question
“But wait a minute. I know the research question. I just don’t know which statistics to use to answer them. What about those?” (I can hear you right now.)
The third step in planning is to choose the statistical test(s) to answer that research question. It’s impossible to list all the things to consider in choosing a statistical test, and there often isn’t just one option.
But here are some general guidelines. The statistical test must:
1. Answer the research question
If your research question requires controlling for covariates, your test needs to have that ability. If the research question is about group differences, the test needs to be able to compare groups. This is why being specific is so important.
2. Take into account the design of the study
Unless it was designed to accommodate other situations, most statistical tests assume simple random samples of independent measurements. If your sample is stratified or clustered; if measurements are repeated over time or space; or some other design issue led measurements to be beyond simple, the test needs to accommodate that.
3. Take into account the level of measurement and distribution of the independent and dependent variables
This will ultimately affect which assumptions are and are not met. The exact same research question from the same design will use different statistical methods if the dependent variable is measured by a categorical variable than if it’s measured by a numerical variable.
4. Deal with any issues in the data
This includes influential outliers, multicollinearity, truncation and censoring, small sample sizes, and missing data. Unlike the three issues above, you can’t always anticipate data issues, and you can’t always deal with them in the main analysis. You may have to use preliminary tests to deal with them first.
Sometimes these are very straightforward and the appropriate analysis is clear. More often it’s not.
Sometimes you don’t realize the data issues or the variable types you’re working with until you dig into the data a bit.
So make a plan. It will still help you keep on track. But it is not written in stone and following it to the letter will only decrease the quality of your analysis.
This is a great time to talk it over with your statistical advisor.
Updated April 22, 2025
Just a thank you! As I collect data for my dissertation research (finally!), I have window-sized sticky notes and white boards with your advice all over my office. Your succinct and clear articles are extremely helpful and have answered or will answer most of my methodology questions. My graduation adviser and I appreciate it.
Hi Michele,
You’re welcome! So glad to be of help.
Nice and concise guide. Thanks.
No comment I’m interested about your work it’s really helps me
May I get a PDF of the above article.
Dear Karen,
Thank you very much for your thoughtful and really helpful suggestions.
There is a lot to learn from them, in particular for students of Ecology and Environmental Studies who are about to start their research projects. They are particularly helpful for those working outdoors, away from the controlled environment of lab experiments.
Stay safe & healthy,
Have a happy week end
luis gonzalo
Dear Karen
I really appreciate your good work. it is really an eye opener. I would like to have information or more detail on data coding and cleaning.
Thank you
I pulled up this site and let me tell you. It has a been up and down as to where to find the best statistical information. Well, I guess I need not research further. I can blocked these concept styles and later apply these strategies in business meeting. Assistance isn’t always recognized vehemently. Thanks for your assistance.
Thanks, Don. Glad you find it helpful.
I have really benefited from your writings. I stumbled into your website when I was searching for some details on sample estimate. I do not have any questions now but I really appreciate your works.
Many thanks