The practice of choosing predictors for a regression model, called model building, is an area of real craft.
There are many possible strategies and approaches and they all work well in some situations. Every one of them requires making a lot of decisions along the way. As you make decisions, one danger to look out for is overfitting—creating a model that is too complex for the the data.
What Overfitting Looks Like
Overfitting can sneak up on you. When it occurs, everything looks great. You have strong model fit statistics. You have large coefficients, with small p-values.
An overfit model appears to predict well with the existing sample of data. But unfortunately, it doesn’t reflect the population.
Regression coefficients are too large.
An overfit model overstates confidence intervals and understates p-values.
It does not fit future observations.
And most importantly, it does not replicate.
It’s like custom-tailoring a suit to a tall, thin individual with especially narrow shoulders and long arms, then hoping to sell it off the rack to the general public.
It will look great on the person you made it for, but it won’t work for (just about) anyone else.
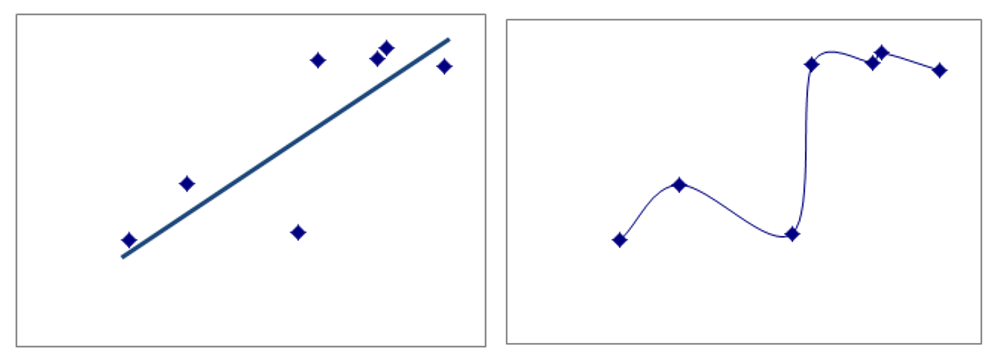
A visual example of overfitting in regression
Below we see two scatter plots with the same data. I’ve chosen this to be a bit of an extreme example, just so you can visualize it.
On the left is a linear model for these points, and on the right is a model that fits the data pretty perfectly. The model on the right uses many more regression parameters and is overfit.
You can see why this model on the right looks great for this data set. But the only way it could work with another sample is if the points were in nearly the exact same places. It’s too customized for the data in this sample.
How and when does overfitting occur?
Models with multiplicative effects
Multiplicative effects include polynomials—quadratic, cubic, etc., and interactions. These terms aren’t generally bad, but they have the potential to add a lot of complexity to a model.
Models with many predictor variables
This is especially true for small data sets. Harrell describes a rule of thumb to avoid overfitting of a minimum of 10 observations per regression parameter in the model. Remember that each numerical predictor in the model adds a parameter. Each categorical predictor in the model adds k-1 parameters, where k is the number of categories.
So a small data set of 50 observations (much larger than my example above!) should have no more than 5 parameters, at a maximum.
Automated models
There are a number of automated model selection techniques. You may have heard them called stepwise regression; or forward or backward selection. They’re great for quickly finding the predictors that are most predictive.
Unfortunately, they’re also prone to overfitting. Newer versions of automated models, like LASSO, have been develop to specifically avoid overfitting.
Ways to avoid overfitting in regression
Use large samples whenever possible. If you have a small sample, you’ll be limited in the number of predictors you can include.
Validate the model. There are many ways to do this, such as testing it on another sample or through resampling techniques such as bootstrapping and jackknifing.
Use scientific theory in model selection. Even models whose sole purpose is prediction benefit from thoughtful reflection about which variables should be included in a model.
A great reference if you want to learn more is Harrell, Frank (2015). Regression Modeling Strategies.

Hi Karen,
Can you say more about bootstrapping, and exactly how this would prevent over-fitting? Maybe in a new post. Thank you!
Dear Karen
Thank you for your lessons which are always most welcome!
Unfortunately I can’t attend your seminars because I can’t understand the spoken English, which is really a pitty!
You are a competent and wise teacher.
Cheers!!!