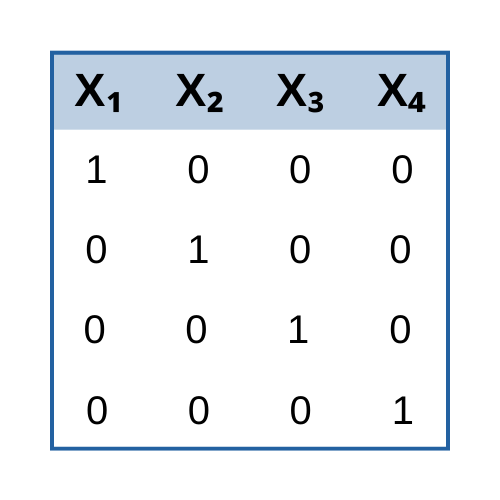
new blog post: Member Training: Dummy and Effect Coding
Previous Posts
I received received a question about controlling for inflated Type I error through Bonferroni corrections in nonparametric tests. Here’s the specific question and my quick answer: My colleague is applying non parametric (Kruskal-Wallis) to check for differences between groups. There are 12 groups and test showed that there is significant difference in the groups. However, […]
Missing Data, and multiple imputation specifically, is one area of statistics that is changing rapidly. Research is still ongoing, and each year new findings on best practices and new techniques in software appear. The downside for researchers is that some of the recommendations missing data statisticians were making even five years ago have changed.
One of the biggest questions I get is about the difference between mediators, moderators, and how they both differ from control variables. I recently found a fabulous free video tutorial on the difference between mediators, moderators, and suppressor variables, by Jeremy Taylor at Stats Make Me Cry. The witty example is about the different types […]
Have you ever needed to do some major data management in SPSS and ended up with a syntax program that’s pages long? This is the kind you couldn’t even do with the menus, because you’d tear your hair out with frustration because it took you four weeks to create some new variables. I hope you’ve […]
1. For a general overview of modeling count variables, you can get free access to the video recording of one of my The Craft of Statistical Analysis Webinars: Poisson and Negative Binomial for Count Outcomes 2. One of my favorite books on Categorical Data Analysis is: Long, J. Scott. (1997). Regression models for Categorical and […]
There are quite a few types of outcome variables that will never meet ordinary linear model’s assumption of normally distributed residuals. A non-normal outcome variable can have normally distribued residuals, but it does need to be continuous, unbounded, and measured on an interval or ratio scale. Categorical outcome variables clearly don’t fit this requirement, so […]
One of the most anxiety-laden questions I get from researchers is whether their analysis is “right.” I’m always slightly uncomfortable with that word. Often there is no one right analysis. It’s like finding Mr. or Ms. or Mx. Right. Most of the time, there is not just one Right. But there are many that are clearly […]
While there are a number of distributional assumptions in regression models, one distribution that has no assumptions is that of any predictor (i.e. independent) variables. It’s because regression models are directional. In a correlation, there is no direction. Y and X are interchangeable. If you switched them, you’d get the same correlation coefficient. But regression […]
Yesterday I gave a little quiz about interpreting regression coefficients. Today I’m giving you the answers. If you want to try it yourself before you see the answers, go here. (It’s truly little, but if you’re like me, you just cannot resist testing yourself). True or False? 1. When you add an interaction to a […]
Here’s a little quiz: True or False? 1. When you add an interaction to a regression model, you can still evaluate the main effects of the terms that make up the interaction, just like in ANOVA. 2. The intercept is usually meaningless in a regression model.
 stat skill-building compass
stat skill-building compass