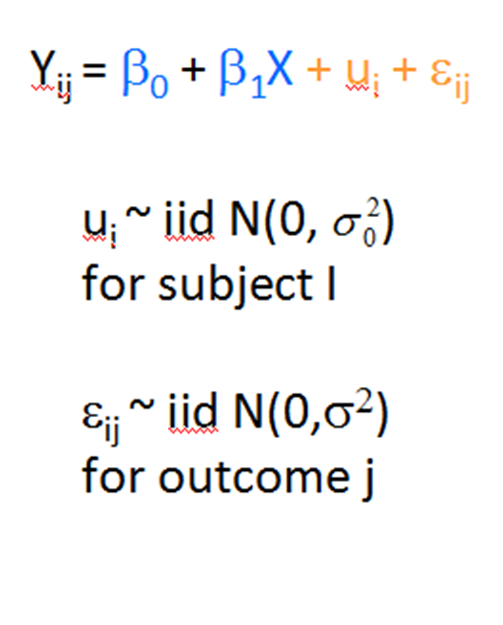I recently received a great question in a comment about whether the assumptions of normality, constant variance, and independence in linear models are about the errors, εi, or the response variable, Yi.
I recently received a great question in a comment about whether the assumptions of normality, constant variance, and independence in linear models are about the errors, εi, or the response variable, Yi.
The asker had a situation where Y, the response, was not normally distributed, but the residuals were.
Quick Answer: It’s just the errors.
In fact, if you look at any (good) statistics textbook on linear models, you’ll see below the model, stating the assumptions: (more…)
A well-fitting regression model results in predicted values close to the observed data values. The mean model, which uses the mean for every predicted value, generally would be used if there were no useful predictor variables. The fit of a proposed regression model should therefore be better than the fit of the mean model. But how do you measure that model fit?
(more…)
In part 3 of this series, we explored the Stata graphics menu. In this post, let’s look at the Stata Statistics menu.
Statistics Menu

Let’s use the Statistics menu to see if price varies by car origin (foreign).
We are testing whether a continuous variable has a different mean for the two categories of a categorical variable. So we should do a 2-sample t-test. (more…)
If you have run mixed models much at all, you have undoubtedly been haunted by some version of this very obtuse warning: “The 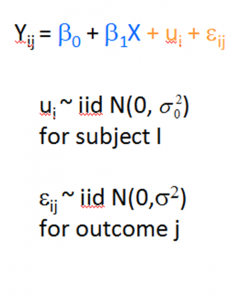 Hessian (or G or D) Matrix is not positive definite. Convergence has stopped.”
Hessian (or G or D) Matrix is not positive definite. Convergence has stopped.”
Or “The Model has not Converged. Parameter Estimates from the last iteration are displayed.”
What on earth does that mean?
Let’s start with some background. If you’ve never taken matrix algebra, (more…)
One of those tricky, but necessary, concepts in statistics is the difference between crossed and nested factors.
As a reminder, a factor is any categorical independent variable. In experiments, or any randomized designs, these factors are often manipulated. Experimental manipulations (like Treatment vs. Control) are factors.
Observational categorical predictors, such as gender, time point, poverty status, etc., are also factors. Whether the factor is observational or manipulated won’t affect the analysis, but it will affect the conclusions you draw from the results.
(more…)
In statistical practice, there are many situations where best practices are clear. There are many, though, where they aren’t. The granddaddy of these practices is adjusting p-values when you make multiple comparisons. There are good reasons to do it and good reasons not to. It depends on the situation.
At the heart of the issue is a concept called Family-wise Error Rate (FWER). FWER is the probability that
(more…)