
In a previous post , Using the Same Sample for Different Models in Stata, we examined how to use the same sample when comparing regression models. Using different samples in our models could lead to erroneous conclusions when interpreting results.
But excluding observations can also result in inaccurate results.
The coefficient for the variable “frequent religious attendance” was negative 58 in model 3 and then rose to a positive 6 in model 4 when income was included. If we didn’t control for income we might conclude that frequent religious attendance leads to a lower mental health composite score.
When we controlled for income we noticed that our sample size decreased from 2,067 to 1,683. Using the same 1,683 observations in model 3a that we used in model 4 had a significant impact on the coefficient of the religious attendance variable for model 3.
Note: regression analysis in Stata drops all observations that have a missing value for any one of the variables used in the model. (This is knows as listwise deletion or complete case analysis).
So a person who does not report their income level is included in model_3 but not in model_4.
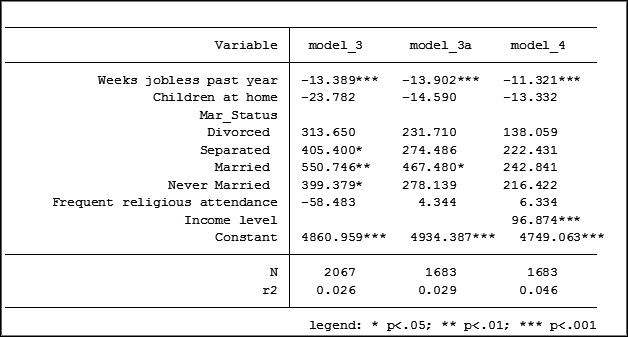
Is there a big difference between the 1,683 observations used in model 4 and the 384 observations that were not used in model 4 but were used in model 3?
To examine the differences between the two samples I ran model 3 once more and generated a new variable “in_model_3”.
gen in_model_3=e(sample)
I then created another variable that equals one if the observation is used in model 3 but not in model 4.
gen not_in_model4 =1 if in_model_3==1 & in_model_4==0
I made the variable equal zero if the observation is used in both model 3 and model 4.
replace not_in_model4=0 if in_model_3==1 & in_model_4==1
I then ran model 3 using the observations not in model 4 (named model_3d) and using the observations used in model 4 (named model_3e).
quietly reg MCS2000 UnemployedWksPastCal2000cont NumberBioStepAdoptChildHH2000 i.Mar_Status high_rel_attend if not_in_model4 ==1
estimates store model_3d
quietly reg MCS2000 UnemployedWksPastCal2000cont NumberBioStepAdoptChildHH2000 i.Mar_Status high_rel_attend if not_in_model4 ==0
estimates store model_3e
The results are:
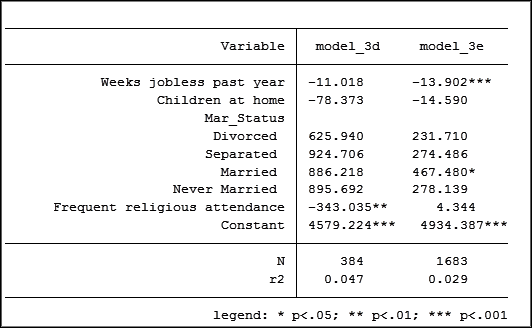
People who don’t report their income level have an average 347 point lower mental health composite score than those who report their income. How do we interpret this?
Let’s check out the summary table for MCS subdivided by whether the observation is in model 4 (not_in_model4).
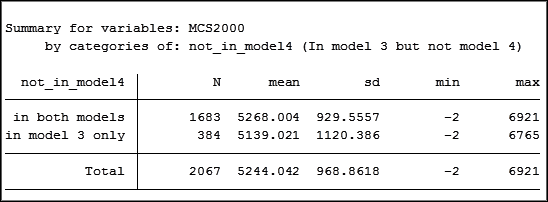
The difference in means between the two groups is 139, much smaller than the difference in the coefficients in model 3 and model 3a of 347.
Something that looks odd is the “minimum” value of negative 2. It’s not possible for the mental composite score to be negative.
These observations need to be treated as missing data.
We’ll change the observations with -2 for MCS to missing. Stata uses “.” (the period) for missing data.
replace MCS2000=. if MCS2000==-2
The two groups are now more similar. A two group t-test confirms there is not a significant difference between the means of the two groups.
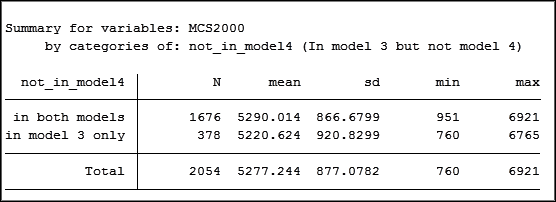
Now rerun the models:
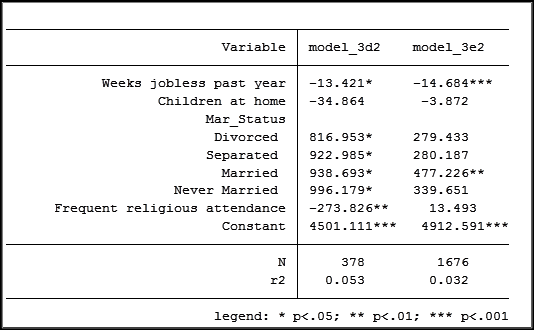
The difference between the coefficients for religious attendance is still significantly different. But it has decreased from 347 to 286 as a result of eliminating the 13 observations with a value of -2.
What else might be influencing the difference in coefficients? Does the manner in which frequent religious attendance is defined (3 or more times per month) affect the outcome?
Survey researchers generally agree that people with low income are less likely to answer a survey question regarding their income level. Is that impacting the results?
Is there another variable that we are not controlling for that is affecting the results?
What story might these missing data tell?
Jeff Meyer is a statistical consultant with The Analysis Factor, a stats mentor for Statistically Speaking membership, and a workshop instructor. Read more about Jeff here.

Leave a Reply