Not too long ago, a colleague mentioned that while he does a lot of study design these days, he no longer does much data analysis.
His main reason was that 80% of the work in data analysis is preparing the data for analysis. Data preparation is s-l-o-w and he found that few colleagues and clients understood this.
Consequently, he was running into expectations that he should analyze a raw data set in an hour or so.
You know, by clicking a few buttons.
I see this as well with researchers new to data analysis. While they know it will take longer than an hour, they still have unrealistic expectations about how long it takes.
So I am here to tell you, the time-consuming part is preparing the data. Weeks is a realistic time frame. Hours is not.
(Feel free to send this to your colleagues who want instant results.)
There are three parts to preparing data: cleaning it, creating necessary variables, and formatting all variables.
Data Cleaning
Data cleaning means finding and eliminating errors in the data. How you approach it depends on how large the data set is, but the kinds of things you’re looking for are:
- Impossible or otherwise incorrect values for specific variables
- Cases in the data who met exclusion criteria and shouldn’t be in the study
- Duplicate cases
- Missing data and outliers (don’t delete all outliers, but you may need to investigate to see if one is an error)
- Skip-pattern or logic breakdowns
- Making sure that the same value of string variables is always written the same way (male ≠ Male in most statistical software).
You can’t avoid data cleaning and it always takes a while, but there are ways to make it more efficient. For example, rather than search through the data set for impossible values, print a table of data values outside a normal range, along with subject ids.
This is where learning how to code in your statistical software of choice really helps. You’ll need to subset your data using IF statements to find those impossible values.
But if your data set is anything but small, you can also save yourself a lot of time, code, and errors by incorporating efficiencies like loops and macros so that you can perform some of these checks on many variables at once.
Creating New Variables
Once the data are free of errors, you need to set up the variables that will directly answer your research questions.
It’s a rare data set in which every variable you need is measured directly.
So you may need to do a lot of recoding and computing of variables.
Examples include:
- Creating change scores
- Creating indices from scales
- Reverse coding scale items
- Combining too-small-to-use categories of nominal variables
- Centering variables
- Restructuring data from wide format to long (or the reverse)
And of course, part of creating each new variable is double-checking that it worked correctly.
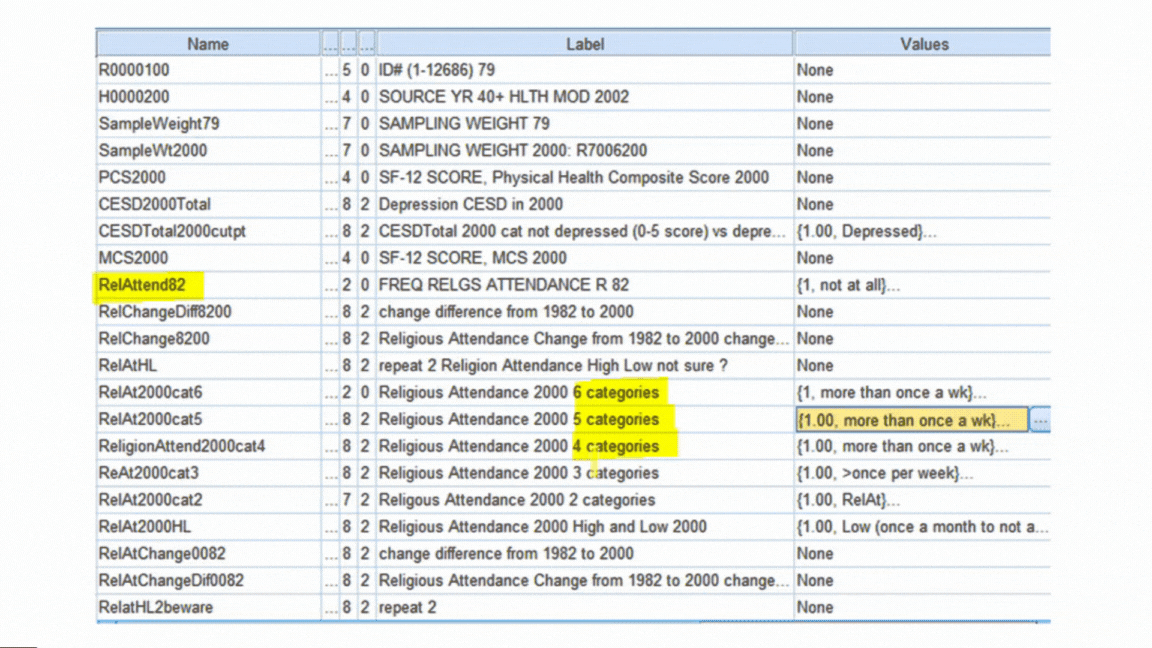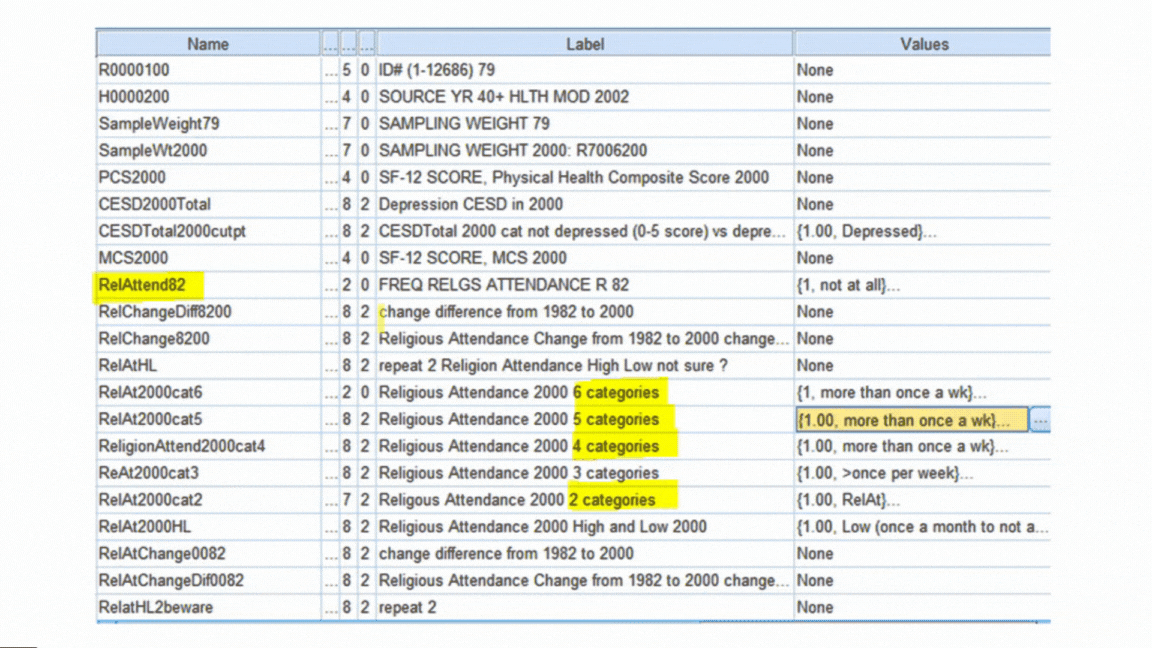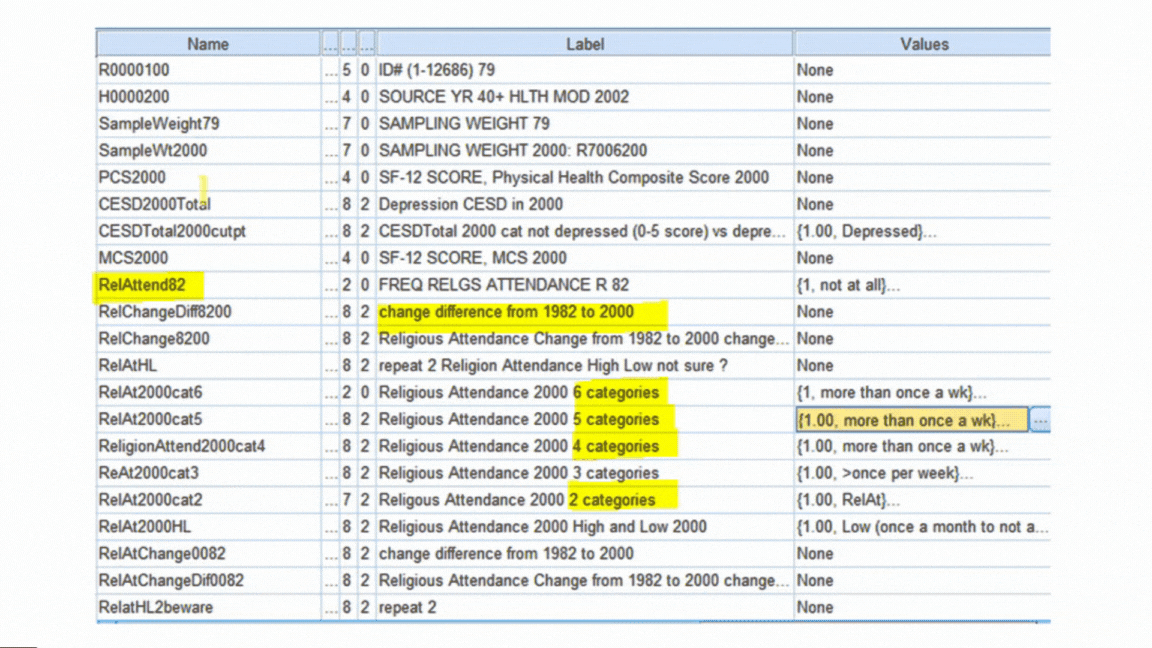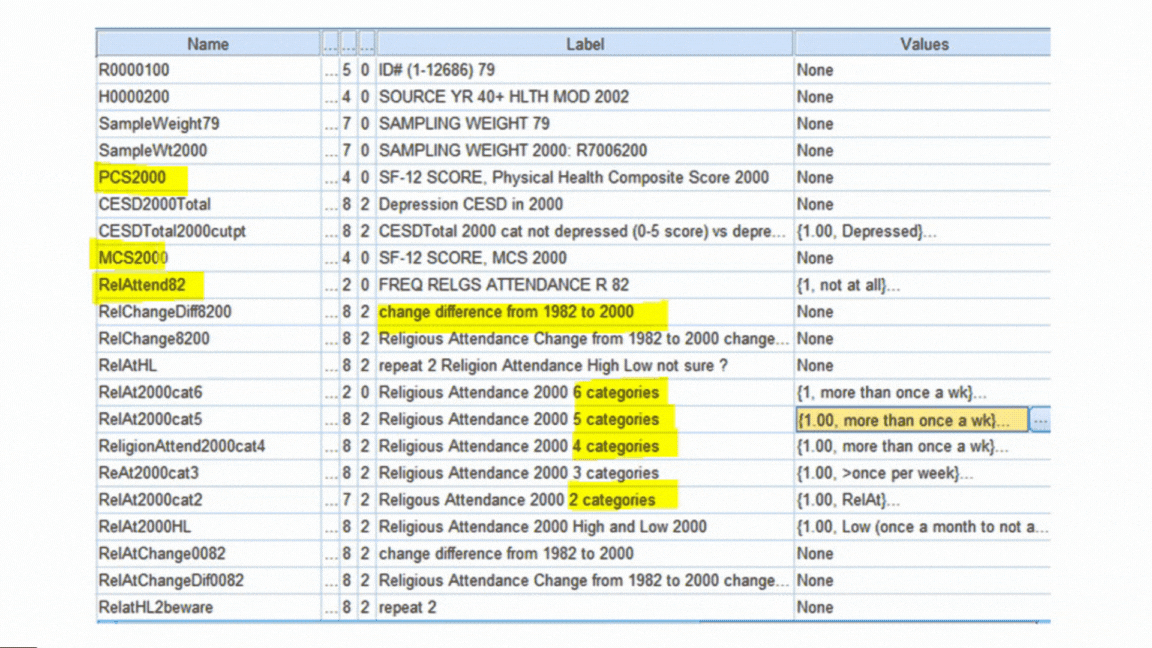
Formatting Variables
Both original and newly created variables need to be formatted correctly for two reasons:
First, so your software works with them correctly. Failing to format a missing value code or a dummy variable correctly will have major consequences for your data analysis.
Second, it’s much faster to run the analyses and interpret results if you don’t have to keep looking up which variable Q156 is.
Examples include:
- Setting all missing data codes so missing data are treated as such
- Formatting date variables as dates, numerical variables as numbers, etc.
- Labeling all variables and categorical values so you don’t have to keep looking them up.
All of these steps require a solid knowledge of how to manage data in your statistical software. Each one approaches them a little differently.
It’s also very important to keep track of and be able to easily redo all your steps. Always assume you’ll have to redo something. So use (or record) syntax, not only menus.

I’ve had interest in pursuing data analysis for quite a long time. It’s an area I’d be glad and give all my might and strength in. Please consider me for the opportunity. Thank you.
Totally agree!
Sadly for me, it’s not the colleagues but the clients who are urgent to see the results. So many times I’ve been asked to analyze, and produce a report of survey data within 1 day or even within 5 hours.
5 hours! Oh my…
Thank you so much. This is a relief and an encouragement. I thought after data collection next step was analysis and writing. I never understood there is a big step in between – data management. Which for me required I learn a software. The basics first. Real learning of state occurred concurrently as I cleaned data. It has taken me One year and 8 months of my PhD!
Thank you for pulling that all together.
It caused me to bookmark your page.
The ‘Tidyverse’ in R is very useful as is keeping data in mySQL or mariaDB databases and accessing them from R.
True: This is the reality but often gets too little attention among researchers!
An underused data cleaning/validation procedure in SPSS Statistics is the VALIDATEDATA procedure. It does a number of basic checks on variables such as looking for a high percentage of missing values, but it also allows definition of single- and cross-variable rules that can check for invalid values, skip logic violations etc. Although it can be tedious to set up these rules, rules can be saved in a library and reused. Statistics comes with a bunch of predefined rules.
I agree very much.
As a Psychologist the data of my experiments are comparingly small. But still, doing the actual statistical analysis does not take up so much time. Getting your data in shape to do any reasonable and valid analyses does.
Tidying your dataset and creating variables really takes around ~ 80% of the time you spend with it. And it’s not like you tidy it and then it’s done. Most times you come up with another interesting way to get some insights with your data but then you find out that you have to create another variable for this calculation and it’s back to tidying data and creating variables.