by Danielle Bodicoat
Statistics can tell us a lot about our data, but it’s also important to consider where the underlying data came from when interpreting results, whether they’re our own or somebody else’s.
Not all evidence is created equally, and we should place more trust in some types of evidence than others.
In medical research, there’s a well-known evidence hierarchy that ranks the main types of evidence. It looks like this:
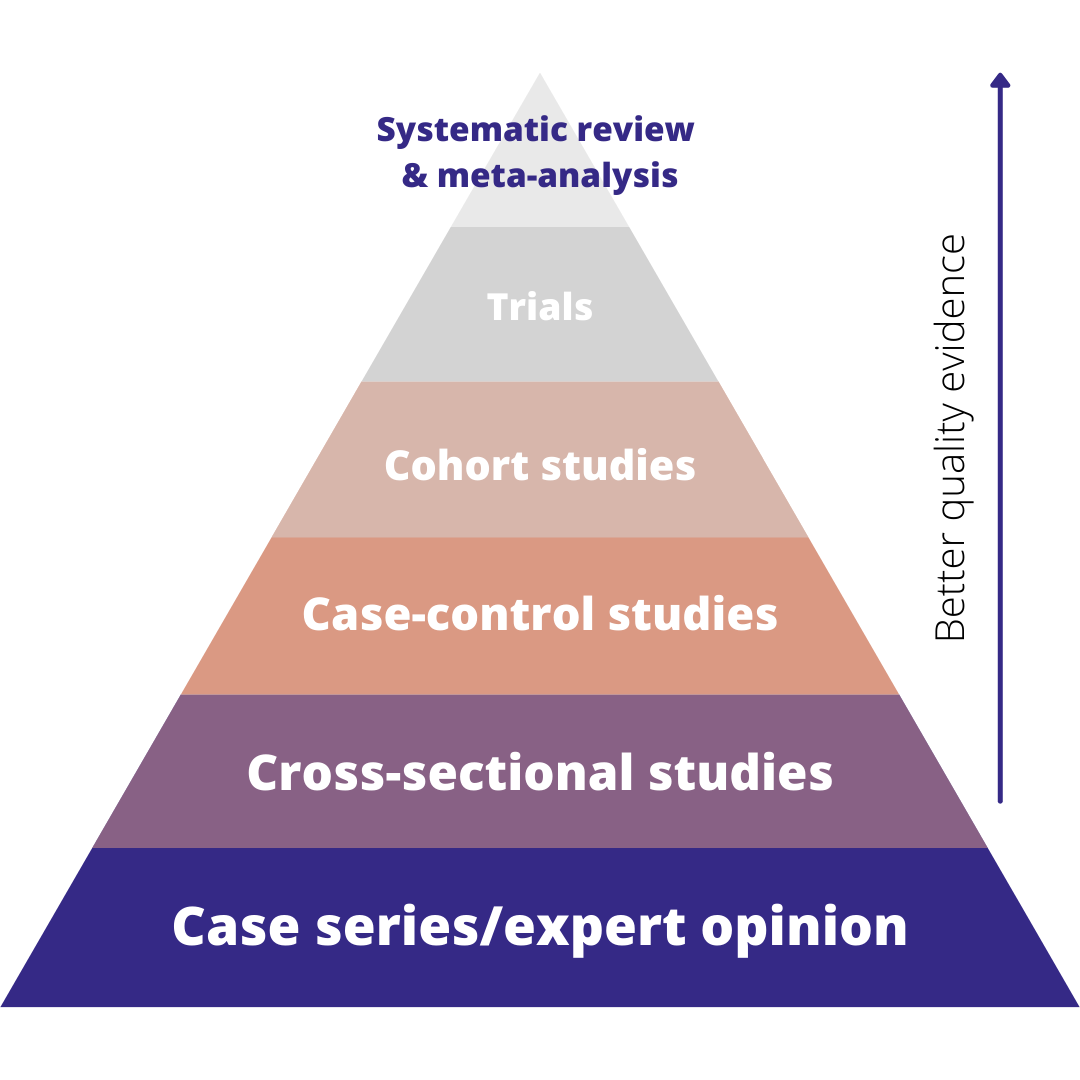
The hierarchy basically shows that the best quality evidence we have comes from systematic reviews, followed by trials, then observational studies. Expert opinion is the lowest form of evidence. Whilst this hierarchy, and some of the specific study types, are mostly used for medical research, the concept translates well to other disciplines.
Below, we’ll walk through each level of the hierarchy, what it is and how to analyze it.
But there’s a caveat!
The quality of the evidence will also depend on how well the study is conducted. So, for example, a large, well-conducted trial might be better than a poorly-conducted, biased systematic review.
For this article, we’ll assume everybody has done a great job and we’re talking about well-conducted studies.
Systematic reviews
Systematic reviews are a specialist type of literature review. We’re essentially trying to find all of the available evidence on a particular research question. The evidence might be published or unpublished (grey literature).
We then combine all of that evidence either qualitatively (narrative review) or quantitatively (meta-analysis) to get a definitive answer to our research question.
This type of evidence is top of the hierarchy because systematic reviews are:
- Objective – there should be no opinion or selection bias involved when choosing which evidence to include in a systematic review
- Comprehensive – includes all of the evidence on a topic
- Precise – a review should answer a very specific research question
- Reproducible – if somebody else followed the same methodology then they should get the exact same answer.
Trials
Trials are tests or experiments designed to answer a specific research question. They have an experimental and control group, and units of observation (such as people) are allocated randomly to each group. This random allocation, along with some other good practices, helps to keep trials unbiased and that’s why they appear second in the hierarchy.
As with any analysis that we do, lots of different things will affect the approach that we take. However, the design of trials means that often we can use fairly simple statistical methods since there may not be any confounders to adjust for.
The main exception to this is where the randomization has been stratified, in which case you will need to adjust for the stratification factors in your analysis.
We also have a known direction of effect because of the study design, which affects our choice of analysis. Based on all of this, trials will typically be analyzed using a generalized linear model.
Cohort studies
In this type of study, we take a group of people (or whatever else we’re interested in) with a characteristic or exposure that we’re interested in, and a group without that characteristic. We then follow them up for a period of time to see whether our outcome of interest develops more often in the exposed group than the unexposed group.
This is the strongest form of non-experimental evidence that we have, because we follow unbiased groups (i.e. when we start the study we have no idea who will develop the outcome of interest).
This design works best where you have a fairly common outcome, otherwise you wouldn’t have any events to analyze. It can also be a great design when you’ve got a rare exposure so that you can make sure you have plenty of exposed people in your study.
People will be followed for different lengths of time. Some will choose to withdraw from the study. You’ll lose touch with others and not be able to find out whether the outcome occurred. Some will develop the outcome of interest at which point you may stop following them up.
We need to account for these differences in follow-up time in our analysis, so we’ll typically use approaches that allow us to include it, such as survival analysis or a comparison of the incidence rates in the exposed and unexposed groups to estimate an incidence rate ratio.
Case-control studies
Case-control studies are sort of the opposite of cohort studies in that we select a group with our outcome of interest (cases), and a group without it (controls). We then look back to see whether the cases were more likely than controls to have been exposed to the potential causal factor that we’re interested in.
Case-control studies work best for rare outcomes and common exposures. Our outcome here is the binary case/control status so this type of study is typically analyzed using logistic regression.
Cross-sectional studies
In this type of study, we just look at a single-point in time to get a ‘snapshot’ of what is happening. This means that everything is measured at the same point in time, although we can ask about the past.
They are particularly useful for measuring prevalence, i.e. how common something is within a population of interest. There is no time element to include in the analyses so again they are typically analyzed using a generalized linear model, though as always your choice of analysis will depend on your research question.
Case-series and expert opinion
In case-series, everybody with an exposure, or outcome, of interest is included in a study. They are typically used in medical research and are often based on medical notes from one hospital.
Because everybody with the exposure or outcome is included, there is no comparator group, and so it isn’t possible to calculate a relative risk. Case-series are often described using a narrative review, rather than analytical methods.
Similarly, expert opinion papers often don’t include any analysis. Whilst they can be very helpful in terms of providing context, they are subjective in nature and so they don’t provide a strong form of evidence.
Danielle Bodicoat works with health researchers helping them to get confident with using statistics to analyze their data. She’s an escaped academic now working as a medical statistics consultant through her company, Simplified Data. She has spent nearly 15 years designing, conducting and supervising statistical analyses, and has 80+ peer-reviewed publications.
Leave a Reply